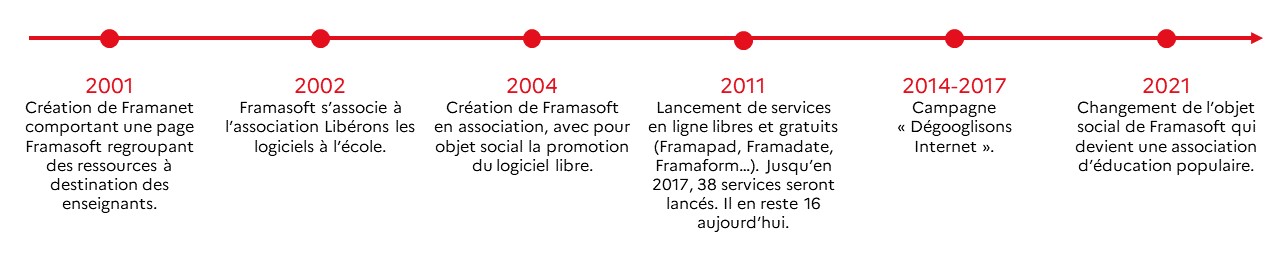
Gilles Dowek n’est plus parmi nous depuis le 21 juillet 2025. Il était informaticien, logicien, philosophe aussi. Il est né le 20 décembre 1966 et après des études à Polytechnique et une thèse d’informatique sous la direction de Gérard Huet, en 1991, il est devenu chercheur à l’Inria. C’est Serge Abiteboul et Claude Kirchner qui nous parlent de lui ici. Benjamin Ninassi, Pierre Paradinas, Thierry Viéville.
Sa passion pour la programmation débute tôt : à quinze ans, il conçoit un jeu de Mastermind qui lui vaut, en 1982, le Prix scientifique Philips pour les jeunes. C’est la première de nombreuses distinctions. En 2007, il obtient le Grand prix de philosophie de l’Académie française pour le livre, “Les Métamorphoses du calcul. Une étonnante histoire de mathématiques”. Dans cet ouvrage, il montre comment les mathématiques et la logique se transforment au XXᵉ siècle avec l’intégration de la notion de calcul. Il reçoit le Grand prix d’informatique Inria – Académie des sciences en 2023, et la Médaille Histoire des Sciences et Épistémologie de cette même académie en 2024. Autant de signes qu’il fut l’un des meilleurs scientifiques de son domaine, mais aussi bien plus que cela.
Ses recherches ont porté sur la formalisation des preuves mathématiques, et sur la mécanisation de leur conception. Un logiciel peut alors vérifier la preuve d’un théorème, aider un humain à en trouver une, voire dans certains cas, trouver automatiquement une telle preuve. Si les langages informatiques suffisamment puissants permettent tous d’exprimer les mêmes fonctions, les fonctions calculables, il n’en est pas de même pour l’expression des preuves. Les langages d’expression de preuves sont souvent incomparables. Gilles s’est alors attelé à une tâche ambitieuse : concevoir un langage universel de preuve, Dedukti, capable de représenter des démonstrations issues de divers systèmes logiques, et de faciliter leur traduction mutuelle. Il rêvait d’une bibliothèque universelle de preuves mathématiques.
Gilles a également tenu une place essentielle dans le mouvement qui a conduit à généraliser l’enseignement de l’informatique dans les collèges et lycées français. Il a participé au rapport de l’Académie des sciences “L’enseignement de l’informatique en France : il est urgent de ne plus attendre” (2013), puis à l’élaboration du premier programme officiel et du premier manuel scolaire d’informatique. Signe de la qualité de ses analyses et de ses contributions, il a été nommé au conseil supérieur des programmes en 2023.
Gilles était également un penseur, un philosophe. Il partageait avec son ami Michel Serres le goût de l’illustration lumineuse, du récit juste. Il excellait à rendre limpide l’abstrait, à frapper les esprits par des exemples pertinents, souvent inattendus. C’était un immense passeur de sciences. Ses livres de médiation scientifique ont marqué, tout comme la pièce de théâtre Qui a hacké Garoutzia, coécrite avec Serge Abiteboul et Laurence Devillers, mise en scène à Avignon par Lisa Bretzner.
Gilles a relié sa pensée scientifique riche, informée et d’une largeur remarquable, incluant la science informatique, mais aussi la recherche en quantique, avec l’éthique du numérique en tant que réflexion sur les conduites humaines et les valeurs qui les fondent. Dès le début des années 2000, il s’est associé aux développements des réflexions sur l’impact sociétal des sciences et technologies numériques. Il a participé à la CERNA (Commission de réflexion sur l’éthique de la recherche en sciences et technologies du numérique) puis a été un membre particulièrement actif et apprécié du CNPEN (Comité national pilote d’éthique du numérique) où ses analyses et propositions ont été remarquablement éclairantes. Par sa profonde culture scientifique et sa vision du domaine du numérique, il savait porter des analyses précises et factuelles sur l’état des impacts du numérique sur notre société tout en ayant une vision prospective pertinente et convaincante.
Profondément militant, Gilles a contribué directement à mettre en pratique ses idées, convictions et compétences. Il a présidé l’ARDHIS (Association pour la reconnaissance des droits des personnes homosexuelles et trans à l’immigration et au séjour). Il a été directeur scientifique adjoint d’Inria de 2010 à 2013, Il a contribué à la mise en place effective en France des cours en ligne ouverts et largement disponibles (Mooc) qui se prolongent aujourd’hui dans Fun (France Université Numérique) et le Learning Lab d’Inria. Il a participé au Comité national pilote d’éthique du numérique, et au Conseil national du numérique.
Dans toutes les différentes facettes de sa vie, Gilles a été brillant, original, drôle, doté d’un humour éclairant et parfois impertinent, rigoureux, passionné, chaleureux, admirable dès qu’on le connaissait, et profondément humaniste avant tout.
Il reste pour nous un ami, et pour tous, un modèle.
Serge Abiteboul, Inria et ENS Paris, Claude Kirchner, Président du CCNE du numérique et Inria.
Gilles et Binaire
Gilles a été un des premiers éditeurs du blog binaire. Il est resté un ami fidèle :
Pour un été non binaire : partez avec binaire dans vos favoris.
Nous faisons notre pause estivale avant de revenir partager avec vous des contenus de popularisation sur l’informatique !
À la rentrée nous parlerons à nouveau aussi bien de technologie que de science, d’enseignement, de questions industrielles, d’algorithmes, de data… bref, de tous les sujets en lien avec le monde numérique qui nous entoure …
Et nous le ferons sur une nouvelle plateforme … toujours en lien avec LeMonde.fr mais enrichi de nouveaux partenariats … à suivre.
D’ici là, vous pouvez tout de même passer l’été avec binaire en profitant de nos collections qui contiennent sûrement de beaux articles que vous n’avez pas encore eu le temps de lire :
Parmi toutes les initiatives des organisations internationales en lien avec l’IA, la Commission européenne et de l’Organisation de Coopération et de Développement Économiques, s’associent avec Code.org pour proposer un référentiel d’apprentissage de l’IA et de son usage en éducation (learning with and about IA), ouvert et surtout en cours de construction participative, invitant chacune et chacun à donner son avis. Voyons cela. Benjamin Ninassi et Ikram Chraibi Kaadoud.
Nous sommes dans les années soixante-dix, mille huit cent soixante-dix. Et une monstruosité apparaît : des personnes se mettent à entendre des voix. Celles d’autres personnes … situées à des dizaines de kilomètres. Il y avait de quoi être terrorisé. On l’était. Maléfice ou magie ? Ce qui arrivait… c’étaient les premiers téléphones. Depuis, on a su expliquer à nos enfants comment cela peut marcher (en cours de physique) et quels usages technologiques (dans les cours éponymes) peuvent en être faits, y compris leurs limites (comme les “faux” appels).
Nous sommes dans les années soixante-dix, deux mille soixante-dix. Et les enfants de rigoler, qu’un siècle avant … s’appelait “intelligence artificielle” une bien vieille famille de mécanismes d’I.A., c’est-à-dire d’Inférence Algorithmique, dont le fonctionnement paraissait alors… soit magique, soit potentiellement maléfique. Mais c’était avant. Et, dans cette vision de l’avenir, nous avons toutes et tous appris à la fois (i) comment fonctionnent ces algorithmes et (ii) comment apprendre en s’aidant de tels algorithmes (learn with and about AI) en le faisant avec discernement et parcimonie.
À moins que, dans un futur bien plus dystopique, nous ayons uniquement permis aux personnes d’utiliser sans comprendre («pas besoin … ça marche tout seul »), ni maîtriser (« il suffit de quelques clics, c’est si facile ») ces outils. Ce monde (imaginaire ?! …) serait alors plus fracturé et terrible à vivre qu’un monde totalitaire soumis à l’ultra surveillance comme George Orwell le cauchemardait. Car si notre quotidien (accès à l’information, choix offerts quant à nos décisions), devenu numérique, était aux mains de quelques personnes (par exemple “les plus riches du monde”), c’est notre propre mental qui serait empoisonné, rendu vulnérable par l’ignorance et l’absence d’esprit critique. De plus, au rythme actuel du réchauffement climatique, en 2070 avec une terre à +3°, les enfants ne rigoleront probablement plus beaucoup.
Que cela ne soit pas.
Depuis quelques mois, des deux côtés de l’Atlantique, une équipe apporte une contribution collégiale pour que notre avenir se fasse pour le meilleur quant à ces IAs dont on ne cesse de parler.
Vous avez dit A.I.L.F. ? (AI* Learning Framework**)
(*) Disons “IA”, gardant à l’esprit que ce sont des outils (au pluriel) d’inférence algorithmique, ni moins, ni plus. (**) Un cadre pour l’apprentissage de ces outils que l’on nomme intelligence artificielle.
La maîtrise de l’IA, sa “littératie”, représente les connaissances techniques, les compétences durables et les bonnes attitudes (savoirs, savoir-faire et savoir être) qui permettent d’interagir avec l’IA, de créer avec de tels outils, de la gérer et de la concevoir, tout en évaluant de manière critique ses avantages, ses risques et ses implications éthiques.
C’est tout aussi indispensable que lire, écrire ou compter. Avec plusieurs points communs : – Ce sont des compétences universelles pour toutes et tous, mais avec de grandes variantes culturelles à respecter : tout le monde doit pouvoir apprendre l’IA et utiliser l’IA pour apprendre, et doit pouvoir devenir autonome par rapport à l’IA, mais dans le respect de sa diversité. – Ce sont des compétences interdisciplinaires, qui ont vocation à s’intégrer dans toutes les disciplines concernées, informatique, mathématiques, et technologies, ainsi que les sciences humaines et les formations pédagogiques transversales des élèves. Beaucoup de ces compétences (esprit critique, pensée informatique, résolution de problème) sont déjà partagées – tant mieux – l’apport de ce cadre est d’aider à la faire dans le contexte de l’IA. – Ce sont des compétences pérennes : on parle de savoirs, savoir-faire et savoir être fondamentaux, qui seront encore pertinents lors de l’évolution attendue des outils actuels (de même qu’en informatique on n’apprend pas “le Python” (ou un autre langage) mais les algorithmes et le codage de l’information, en s’appuyant sur tel ou tel langage formel qui peut être amené à changer avec le temps). – Parmi les compléments à apporter à la version actuelle, les impacts environnementaux de l’IA, déjà pris en compte, sont à renforcer : les impacts environnementaux directs de chaque apprentissage, chaque inférence, chaque investissement en faveur d’une solution basée sur l’IA sont déjà réels aujourd’hui, ainsi que les impacts environnementaux délétères indirects de beaucoup de cas d’usage.
Cette littératie cible principalement l’enseignement primaire et secondaire, mais est aussi ouverte au péri et extra scolaire, et à l’éducation familiale.
C’est ici : http://ailiteracyframework.org que nous avons tous les éléments de présentation (avec une version traduite de la page de présentation : https://tinyl.co/3OeN). Il y a même un “prompt” (l’instruction ou la question qui est posée de manière textuelle à un IA avec une interface langagière) pour interroger une IA à propos de cette littératie de l’IA.
Une première version, aboutie et soigneusement revue, est disponible, pour travailler sur des éléments précis. Pas d’erreur ! Elle a évidemment vocation à évoluer et être remodelée, voire questionnée en profondeur, en fonction des relectures et des retours.
Alors… à vous !
Au cours des prochains mois, nous sollicitons les commentaires des parties prenantes du monde entier. Pour participer, visitez www.teachai.org/ailiteracy/review. La version finale du cadre sera publiée en 2026, accompagnée d’exemples de maîtrise de l’IA dans les programmes, l’évaluation et la formation professionnelle.
Thierry Viéville, chercheur Inria.
Ok … 1,2,3 : comment me lancer dès maintenant ?
– Avec la formation ClassCode I.A.I. on se forme sans aucun prérequis technique aux bases de l’IA, pour piger comment ça marche:
Ressource gratuitement utilisable et réutilisable.
– Former les enseignants au contexte, l’usage, la pertinence et les défis de ressources éducatifs mobilisant de l’intelligence artificielle dans un cadre éducatif :
À l’heure ou transition écologique rime souvent avec transition numérique, qu’en est-il réellement des impacts environnementaux du numérique ? Comment dès à présent commencer à agir pour un numérique plus responsable et plus durable ?
« L’année 2025 pourrait bien marquer un tournant décisif pour l’intelligence artificielle en France. En quelques mois à peine, le pays a concentré sur son sol une série d’événements majeurs, des annonces économiques sans précédent, et une mobilisation politique et industrielle rarement vue à cette échelle » C’est par ces propos que Jason RIchard nous partage ici son analyse de ce que les médias ont déjà largement relayé. Serge Abiteboul et Thierry Viéville.
L’IA, longtemps domaine de prospective ou de niche, est désormais partout : dans les discours officiels, dans les stratégies d’investissement, dans les démonstrateurs technologiques, dans les débats publics… Et surtout, elle est devenue un axe structurant de la politique industrielle française. Alors, 2025 : coup d’accélérateur ou effet d’annonce ? Éléments de réponse à mi-parcours d’une année qui, semble avoir placé la France au centre du jeu.
Quatre grands événements au cours de ce premier semestre sont partagés avec plus de détail en annexe de cet article.
Une ambition qui se concrétise
La trajectoire n’est pas nouvelle. Dès 2018, la France avait lancé une stratégie nationale sur l’IA, misant sur l’excellence scientifique, la création de champions technologiques et une volonté de régulation éthique. Mais ce début 2025 a marqué une inflexion nette : ce ne sont plus des promesses ou des feuilles de route, mais des réalisations concrètes, visibles et, surtout, financées.
Sommet Choose France 2025 : plus de 40 milliards d’euros annoncés, l’IA mise à l’honneur.
Sur le plan diplomatique, la France a accueilli à Paris, début février un sommet mondial sur l’action en matière d’IA, réunissant plus de 100 délégations internationales. Sur le plan économique, le sommet Choose France 2025, en mai, a vu l’annonce de 37 milliards d’euros d’investissements étrangers, dont près de 17 milliards spécifiquement orientés vers l’IA et les infrastructures numériques. De nouvelles giga-usines de données, des centres de calcul haute performance, des campus IA… autant de projets qui commencent à prendre racine sur le territoire, dans les Hauts-de-France, en Île-de-France ou encore en Provence. Ce n’est plus seulement une question de stratégie : c’est désormais une réalité industrielle.
Une dynamique entre État, start-ups et investisseurs
World AI Cannes Festival 2025 : l’IA fait son show à Cannes
Ce mouvement est porté par une triple alliance entre l’État, les start-ups de la French Tech et les investisseurs internationaux. L’écosystème s’est structuré. On compte aujourd’hui en France près de 1 000 jeunes pousses spécialisées en IA, dont plusieurs sont devenues des licornes. Des journées entières leur ont été consacrées, à Station F comme au World AI Cannes Festival, et de nombreuses d’entre elles ont profité de ces événements pour nouer des contacts avec des fonds étrangers, tester leurs solutions, ou signer des premiers contrats.
Le gouvernement, de son côté, ne se contente plus d’un rôle de spectateur bienveillant. Il est co-investisseur, catalyseur, diplomate. Des partenariats stratégiques ont été tissés avec des acteurs nord-américains, émiratis, européens… dans une logique de souveraineté numérique partagée. L’objectif est clair : faire de la France un point central pour entraîner, héberger et déployer les modèles d’IA de demain. Avec en ligne de mire, la maîtrise technologique autant que la compétitivité économique.
Des usages concrets… et des questions fondamentales
Station F Business Day 2025 : l’innovation IA made in France
Loin de se limiter aux infrastructures, l’IA s’immisce dans tous les secteurs : santé, énergie, industrie, agriculture, éducation. Certains cas d’usage sont déjà déployés à grande échelle : systèmes d’aide au diagnostic médical, optimisation des réseaux électriques, automatisation de processus industriels, ou encore agents conversationnels dans les services publics. L’heure est à l’intégration, à l’industrialisation, et à l’évaluation.
Mais cette dynamique pose des questions majeures. Comment garantir l’équité des systèmes algorithmiques ? Comment réguler les modèles génératifs qui créent du faux plus vite qu’on ne peut le détecter ? Comment protéger les données, les droits, l’emploi, dans un monde où les machines apprennent plus vite que les institutions ne légifèrent ?
La réponse française est à double détente : soutenir l’innovation sans naïveté, et réguler sans brider. Cela passe par l’appui au futur règlement européen (AI Act), par la participation active aux grands forums internationaux (OCDE, ONU, GPAI), mais aussi par une réflexion de fond sur l’inclusion et la transparence. Cette ligne de crête est peut-être ce qui distingue le plus la posture française sur l’IA en 2025.
Une question ouverte
Sommet Action IA 2025 : Paris capitale mondiale de l’IA
Alors, 2025 est-elle l’année de l’IA en France ? Il est encore trop tôt pour l’affirmer avec certitude. Mais jamais les planètes n’avaient été aussi bien alignées. Les infrastructures arrivent. Les financements suivent. L’écosystème s’organise. Le débat public s’anime. Et l’État joue pleinement son rôle. Ce n’est pas une révolution soudaine, mais plutôt une convergence de trajectoires, diplomatique, économique, technologique et sociale, qui pourrait, si elle se maintient, faire de la France l’un des pôles IA majeurs de la décennie.
Jason Richard, Business Innovation Manager chez Airbus Defence and Space.
Pour aller plus loin
Des articles détaillés sur chacun de ces événements marquants de ce premier semestre 2025 – Sommet pour l’action sur l’intelligence artificielle, Station F Business Day 2025, World AI Cannes Festival 2025, Choose France – sont disponibles ici :
Charles Cuvelliez et Jean-Jacques Quisquater nous proposent en collaboration avec le Data Protection Officer de la Banque Belfius ; Francis Hayen, une discussion sur le dilemme entre le RGPD et la mise en place de caméra augmentée à l’IA pour diminuer le nombre de vols, les oublis, le sous-pesage aux caisses automatiques des supermarchés, qui sont bien nombreux. Que faire pour concilier ce besoin effectif de contrôle et le respect du RGPD ? Et bien la CNIL a émis des lignes directrices, d’aucun diront désopilantes, mais pleines de bon sens. Amusons-nous à les découvrir.Benjamin Ninassi et Thierry Viéville.
C’est le fléau des caisses automatiques des supermarchés : les fraudes ou les oublis, pudiquement appelées démarques inconnues, ou la main lourde qui pèse mal fruits et légumes. Les contrôles aléatoires semblent impuissants. Dans certaines enseignes, il y a même un préposé à la balance aux caisses automatiques. La solution ? L’IA pardi. Malgré le RGPD ? Oui dit la CNIL dans une note de mai 2025.
Cette IA, ce sont des caméras augmentées d’un logiciel d’analyse en temps réel. On les positionne en hauteur pour ne filmer que l’espace de la caisse, mais cela inclut le client, la carte de fidélité, son panier d’achat et les produits à scanner et forcément le client, flouté de préférence. L’algorithme aura appris à reconnaitre des « événements » (identifier ou suivre les produits, les mains des personnes, ou encore la position d’une personne par rapport à la caisse) et contrôler que tout a bien été scanné. En cas d’anomalie, il ne s’agit pas d’arrêter le client mais plus subtilement de programmer un contrôle ou de gêner le client en lui lançant une alerte à l’écran, propose la CNIL qui ne veut pas en faire un outil de surveillance en plus. Cela peut marcher, en effet.
C’est que ces dispositifs collectent des données personnelles : même en floutant ou masquant les images, les personnes fautives sont ré-identifiables, puisqu’il s’agira d’intervenir auprès de la personne. Et il y a les images vidéo dans le magasin, non floutées. La correspondance sera vite faite.
Mais les supermarchés ont un intérêt légitime, dit la CNIL, à traiter ces données de leurs clients (ce qui les dispense de donner leur consentement) pour éviter les pertes causées par les erreurs ou les vols aux caisses automatiques. Avant d’aller sur ce terrain un peu glissant, la CNIL cherche à établir l’absence d’alternative moins intrusive : il n’y en a pas vraiment. Elle cite par exemple les RFID qui font tinter les portiques mais, si c’est possible dans les magasins de vêtements, en supermarché aux milliers de référence, cela n’a pas de sens. Et gare à un nombre élevé de faux positifs, auxquels la CNIL est attentive et elle a raison : être client accusé à tort de frauder, c’est tout sauf agréable. Cela annulera la légitimité de la méthode.
Expérimenter, tester
Il faut qu’un tel mécanisme, intrusif, soit efficace : la CNIL conseille aux enseignes de le tester d’abord. Cela réduit-il les pertes de revenus dans la manière dont le contrôle par IA a été mis en place ? Peut-on discriminer entre effet de dissuasion et erreurs involontaires pour adapter l’intervention du personnel ? Il faut restreindre le périmètre de prise de vue de la caméra le plus possible, limiter le temps de prise de vue (uniquement lors de la transaction) et la stopper au moment de l’intervention du personnel. Il faut informer le client qu’une telle surveillance a lieu et lui donner un certain contrôle sur son déclenchement, tout en étant obligatoire (qu’il n’ait pas l’impression qu’il est filmé à son insu), ne pas créer une « arrestation immédiate » en cas de fraude. Il ne faut pas garder ces données à des fins de preuve ou pour créer une liste noire de clients non grata. Pas de son enregistré, non plus. Ah, si toutes les caméras qui nous espionnent pouvaient procéder ainsi ! C’est de la saine minimisation des données.
Pour la même raison, l’analyse des données doit se faire en local : il est inutile de rapatrier les données sur un cloud où on va évidemment les oublier jusqu’au moment où elles fuiteront.
Le client peut s’opposer à cette collecte et ce traitement de données mais là, c’est simple, il suffit de prévoir des caisses manuelles mais suffisamment pour ne pas trop attendre, sinon ce droit d’opposition est plus difficilement exerçable, ce que n’aime pas le RGPD. D’aucuns y retrouveront le fameux nudge effect de R. Thaler (prix Nobel 2017) à savoir offrir un choix avec des incitants cognitifs pour en préférer une option plutôt que l’autre (sauf que l’incitant est trop pénalisant, le temps d’attente).
Autre question classique dès qu’on parle d’IA : peut-on réutiliser les données pour entrainer l’algorithme, ce qui serait un plus pour diminuer le nombre de faux positifs. C’est plus délicat : il y aura sur ces données, même aux visages floutés, de nombreuses caractéristiques physiques aux mains, aux gestes qui permettront de reconnaitre les gens. Les produits manipulés et achetés peuvent aussi faciliter l’identification des personnes. Ce serait sain dit la CNIL de prévoir la possibilité pour les personnes de s’y opposer et dans tous les autres cas, de ne conserver les données que pour la durée nécessaire à l’amélioration de l’algorithme.
Les caisses automatiques, comme les poinçonneuses de métro, les péages d’autoroute, ce sont des technologies au service de l’émancipation d’une catégorie d’humains qui ont la charge de tâches pénibles, répétitives et ingrates. Mais souvent les possibilités de tricher augmentent de pair et il faut du coup techniquement l’empêcher (sauter la barrière par ex.). L’IA aux caisses automatiques, ce n’est rien de neuf à cet égard.
Mine de rien, toutes ces automatisations réduisent aussi les possibilités de contact social. La CNIL n’évoque pas l’alternative d’une surveillance humaine psychologiquement augmentée, sur place, aux caisses automatiques : imaginez un préposé qui tout en surveillant les caisses, dialogue, discute, reconnait les habitués. C’est le contrôle social qui prévient bien des fraudes.
Quand on sait la faible marge que font les supermarchés, l’IA au service de la vertu des gens, avec toutes ces précautions, n’est-ce pas une bonne chose ?
Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles), Francis Hayen, Délégué à la Protection des Données & Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT).
Sur le blog binaire, nous aimons aussi la fiction, et Henri d’Agrain, nous partage ici une petite nouvelle bien … édifiante. Plaise à la vie que cela reste bien de la fiction. Yves Bertrand & Serge Abiteboul
Dessiné aux bons soins de l’auteur par ChatGPT, qui ne s’est pas fait prier…
Bruxelles, le 4 juillet 2025, par notre envoyé spécial, Jean Pacet-Démayeur
Une décision historique et lourde de conséquences vient bouleverser les relations entre les États-Unis et l’Union européenne. Dans un contexte de tension croissante depuis six mois, le Président Trump a annoncé hier soir, à la veille des célébrations de l’Independence Day, qu’il avait signé un Executive Order avec effet immédiat, interdisant aux entreprises technologiques américaines de délivrer des produits et des services numériques au Danemark, membre de l’Union européenne. Cette mesure de rétorsion, sans précédent entre alliés historiques, est la conséquence du conflit diplomatique majeur que Donald Trump a provoqué en annonçant au début de l’année, et avant d’entrer à la Maison blanche le 20 janvier 2025, son projet d’annexion par les États-Unis du Groenland, y compris par la force armée.
Une annexion qui embrase les relations internationales
Tout a commencé il y a six mois en effet, lorsque Donald Trump a annoncé sa volonté d’annexer le Groenland, éventuellement par la force armée. L’île principale de l’Atlantique Nord représente en effet un atout géostratégique majeur en raison de sa proximité avec les routes maritimes critiques reliant l’Europe, l’Asie et l’Amérique du Nord, ainsi que pour ses riches réserves en matières premières stratégiques. Déjà en 2019, une rumeur prêtait à Donald Trump, au cours de son premier mandat, l’intention d’acheter le Groenland au Danemark.
Malgré des protestations fermes de l’Union européenne et des appels au dialogue international, le Président Donald Trump a justifié sa décision par des impératifs stratégiques et de sécurité nationale. En réponse, le Danemark a saisi le Conseil de sécurité des Nations Unis, appelant à une mobilisation diplomatique mondiale.
Un embargo numérique aux conséquences vertigineuses
Hier soir, dans une escalade sans précédent, la Maison-Blanche a annoncé qu’elle interdisait à toutes les entreprises américaines de la tech de continuer à fournir leurs services au Danemark et à son économie. Cette décision inclut des géants tels que Microsoft, Google, Amazon, Meta et Apple, dont les infrastructures, les logiciels et les plateformes sont omniprésents dans l’économie danoise. Il a par ailleurs annoncé que les États-Unis lèveront cet embargo numérique lorsque le Danemark aura accepté de leur vendre le Groenland à un prix raisonnable et conforme à l’offre d’achat formulée en avril 2025.
Le ministre danois de l’Économie a qualifié cette décision de « déclaration de guerre économique », prévenant que son pays faisait face à une « paralysie imminente ». En effet, le fonctionnement de l’économie danoise repose largement sur les services cloud de fournisseurs américains, tandis que son administration publique et son système éducatif dépendent étroitement d’outils tels que Microsoft 365. Plusieurs organisations professionnelles danoises ont par ailleurs appelé le Gouvernement a engager des négociations avec les États-Unis pour éviter l’effondrement de l’économie du pays.
Les conséquences sociales se font déjà sentir : la plupart des administrations publiques sont à l’arrêt, des milliers d’entreprises se retrouvent coupées de leurs outils de gestion, les services bancaires numériques sont indisponibles, et les citoyens constatent qu’ils ne peuvent plus accéder à leurs services du quotidien comme les applications de messagerie, les réseaux sociaux ou les plateformes de streaming. Les hôpitaux, quant à eux, s’inquiètent de l’accès à leurs systèmes de données patient, majoritairement hébergés sur des serveurs américains.
Une vulnérabilité européenne mise à nu
Cette crise expose cruellement le caractère systémique des dépendances numériques des États européens et de leur économie à l’égard des technologies américaines. Si le Danemark est le seul à être touché, d’autres États européens redoutent des mesures de rétorsions similaires. La Commission européenne, par la voix de sa Présidente, a déclaré que « l’Union européenne déplore de telles attaques contre l’intégrité économique et numérique de l’un de ses membres. » Elle a appelé au dialogue entre les États-Unis et le Danemark et à l’apaisement des tensions. Elle a par ailleurs proposé aux États membres d’apporter un soutien technique au Danemark. Elle suggère enfin de lancer les travaux nécessaires pour accélérer les stratégies d’investissements de l’Union dans des alternatives européennes, notamment en mettant en œuvre les préconisations inscrites dans le rapport que Mario Draghi, l’ancien président de la Banque centrale européenne, lui avait remis en septembre 2024.
Les réponses possibles du Danemark
Face à cette situation inédite, le gouvernement danois tente de réagir. Des négociations d’urgence ont été ouvertes avec des acteurs non américains pour assurer une transition vers des systèmes alternatifs, mais de telles démarches de migration prendront des mois, voire des années. Parallèlement, le pays envisage des mesures de rétorsion, comme le blocage des actifs américains sur son territoire, mais son poids économique relativement faible limite ses marges de manœuvre.
En attendant, les citoyens danois se préparent à vivre une crise sans précédent. Certains experts avertissent que cette situation pourrait entraîner une radicalisation de l’opinion publique contre les États-Unis, renforçant les partis politiques favorables à un rapprochement avec d’autres puissances mondiales.
Une fracture durable ?
Alors que la situation semble s’envenimer, de nombreux observateurs redoutent que cette crise ne marque un tournant dans les relations transatlantiques. L’embargo numérique américain pourrait non seulement remodeler les alliances stratégiques comme l’OTAN, mais aussi accélérer le développement de systèmes technologiques régionaux indépendants, que ce soit en Europe ou ailleurs. Une chose est certaine : le Danemark est devenu, bien malgré lui, le théâtre d’une confrontation qui pourrait redéfinir l’ordre international.
Notre collègue du Cnam, Stéphane Natkin, Prof émérite, suite à l’écoute sur France Inter de Madame Virginie Schwarz, directrice de Météo France à propos du remplacement des modèles mathématiques de prévision par des modèles d’IA… a imaginé ce petit conte. Pierre Paradinas & Thierry Viéville.
Dans les années 1… un jeune homme dénommé Isaac N. se prélassait sous un pommier. Soudain une pomme se détacha du pommier et tomba par terre. Ceci amena immédiatement Isaac N. à se poser la question de la reproductibilité du phénomène. Il sortit de sa poche son smartphone et interrogea son IA CIF (Cat I Farted) ; il lui demanda d’analyser tous les vidéos de chute de pommes que l’on trouvait sur Internet et d’en tirer une prédiction sur la chute des pommes. Le résultat, qui consomma une quantité non négligeable d’énergie, semblait incontestable : Avec une probabilité d’erreur inférieure à 10-24, on peut dire que “Lorsque on lâche une pomme, elle tombe“.
Isaac N. propagea la nouvelle sur les réseaux sociaux et atteignit rapidement plusieurs millions de followers. Certains réitérèrent le procédé en modifiant le prompt : peut-on en tirer la même conclusion pour les poires ou les pêches ?
Mais soudainement aux USA et en Russie apparurent des groupes contestataires les WON’T FALL (WF), qui défendaient des points de vue plus ou moins nuancés et basés, soi-disant, sur un nouveau type de réseaux neuronaux. Selon eux la thèse de Isaac N. était typiquement issue d’une pensée décadente et Wokiste. Non ! les vraies et bonnes pommes ne tombent pas des arbres, en particulier les pommes cultivées aux USA. Ils admettaient qu’il restait un doute relativement aux pommes du Canada et certains types de pommes rouges, relents d’une pensée communiste dépassée.
Mais finalement la conclusion d’Isaac N. s’imposa. Ceci eu des conséquences impressionnantes. Comme Issac N. connaissait l’avenir des pommes, il n’eut pas besoin de trouver pourquoi elles tombent. Il n’inventa donc pas la loi de la gravitation universelle. Cette loi qui aurait permis de comprendre le mouvement des astres mais aussi de construire d’incroyables machines. Tout un pan de la science disparut et, par un méandre des technologies, les ordinateurs aussi…
Mais s’il n’y a plus d’ordinateurs Isaac N. ne peut pas interroger CIF. Il doit donc s’appuyer sur sa très grande Intelligence Naturelle (IN), découvrir la loi de la gravitation universelle et toute cette histoire n’existe pas…
Référence. Entretien avec la PDG de Météo-France, Virginie Schwarz, invitée d’Emmanuel Duteil dans l’émission « On arrête pas l’éco », samedi 19 avril, on peut retrouver l’émission de France Inter.
Note. Ce n’est pas le seul conte autour de ce vieux paradoxe et d’une vision humoristique et prémonitoire de l’IA, dès les années 1970, un des pères de l’informatique française Jacques Arsac, écrivait -pour rire- “Sorbon un générateur automatique de thèses“, qui mettait en scène l’idée d’une intelligence algorithmique qui remplacerait la création humaine, au niveau scientifique.
Un essai de Gérard Berry, Odile Jacob, 2025Nous sommes aujourd’hui capables de mesurer et de partager le temps avec une précision stupéfiante. Mais en comprenons-nous vraiment toutes les dimensions ? Sommes-nous conscients des nouveaux enjeux, souvent cruciaux, que les systèmes ultra-performants qui rythment notre quotidien soulèvent ?
Dans cet ouvrage, Gérard Berry propose une présentation totalement inédite du sujet. Il ne se contente pas d’exposer des faits scientifiques ou techniques. Dans un style qui lui ressemble tellement, en véritable conteur, il nous parle du temps, avec sérieux, poésie, humour, avec une fraîcheur qui réjouit.
Professeur au Collège de France, ancien titulaire de la chaire Algorithmes, machines et langages (2012–2019), médaille d’or du CNRS et membre des Académies des sciences et des technologies, Gérard Berry est également l’auteur de L’hyperpuissance de l’informatique. Il nous livre ici un regard aussi érudit qu’original sur ce que le temps signifie vraiment.
J’ai consacré toute ma carrière professionnelle à la cybersécurité, depuis ma thèse portant sur la détection d’intrusions. À cette époque, j’utilisais des outils nommé « algorithmes génétiques », que l’on pourrait classer dans le domaine de l’intelligence artificielle aujourd’hui. J’ai soutenu cette thèse en 1994, puis j’ai suivi une carrière classique d’enseignant-chercheur, à Supélec puis à CentraleSupélec. J’ai encadré mes premiers doctorants, obtenu une habilitation à diriger des recherches, puis été nommé professeur. J’ai ensuite créé une équipe qui a d’abord été une équipe propre à CentraleSupélec, puis une équipe d’accueil (EA 4034) et, enfin, une équipe Inria à partir de 2011. En 2015, tout en restant à CentraleSupélec, je suis devenu délégué scientifique du centre Inria à Rennes. Enfin, à partir de 2019, je suis devenu adjoint de Jean-Frédéric Gerbeau à la direction scientifique d’Inria, fonction que j’ai occupée jusqu’en mars 2025, date à laquelle j’ai été nommé directeur du programme cybersécurité de l’agence de programme du numérique.
Qui/qu’est-ce qui sera impacté par l’IA dans la cybersécurité ?
La cybersécurité se compose de divers sous-domaines, assez disjoints les uns des autres du point de vue de leurs objectifs et des outils qu’ils emploient. Citons par exemple la cryptographie, la sécurité des systèmes d’exploitation, la sécurité des réseaux, la supervision de la sécurité. L’impact de l’intelligence artificielle (IA), ou plus précisément de l’apprentissage automatique, varie considérablement selon les sous-domaines.
Par exemple, en cryptographie, l’impact est, me semble-t-il, quasi-inexistant. En effet, il est peu probable qu’un nouveau mécanisme cryptographique soit développé grâce à l’apprentissage automatique. La mise au point d’un tel mécanisme nécessite un travail d’identification de problèmes mathématiques complexes et de conception d’algorithmes de chiffrement basées sur ces problèmes. Il faut également dimensionner correctement les constantes qui entrent en jeu, comme bien évidemment la taille des clés, afin de garantir une marge de sécurité suffisante, compte tenu de la puissance de calcul nécessaire pour « casser » ces algorithmes de chiffrement. Il y a donc peu de place pour l’apprentissage automatique dans ce domaine, et je doute qu’il y en ait à court terme. De même, le « cassage » d’un algorithme (ce qu’on appelle la cryptanalyse) repose sur des méthodes spécifiques qui, à ma connaissance, ne peuvent être remplacées par l’apprentissage automatique.
À l’inverse, le domaine de la supervision de la sécurité (détection des attaques en cours sur un système informatique) est assez fortement impacté. Dans le monde industriel, jusqu’à aujourd’hui, les techniques principales de détection d’intrusions sont dites à base de signatures. Il s’agit de spécifier les symptômes des attaques, puis de rechercher des traces de ces symptômes dans les données à analyser, qui peuvent être des journaux système, des journaux applicatifs ou du trafic réseau. Ce dernier type de données est généralement utilisé, car il a un impact minimal sur les systèmes. Ainsi, si certains symptômes sont observés, par exemple dans les en-têtes des paquets réseau, des alertes sont déclenchées et envoyées à des experts pour analyse. En particulier, l’objectif de ces experts est d’éliminer les fausses alertes, qui sont très nombreuses. Dans cette démarche globale de « supervision de la sécurité », plusieurs opportunités s’ouvrent pour l’apprentissage automatique, tant pour la production d’alertes que pour le tri de ces alertes.
Premièrement, en ce qui concerne la production, au lieu de se baser sur l’identification de symptômes d’attaque (notons que l’intelligence artificielle dite « symbolique » pourrait le faire), il est possible de raisonner par la négation. Il s’agit alors de définir ce qu’est la normalité du fonctionnement d’un système et d’identifier ensuite les déviations par rapport à cette normalité. C’est ce que l’on appelle la détection d’anomalies, technique connue depuis longtemps. Pour effectuer une détection d’anomalies, des statistiques étaient classiquement utilisées. Aujourd’hui, au lieu de se baser uniquement sur des mathématiques, on utilise plutôt l’apprentissage : on apprend des modèles correspondant au fonctionnement normal de certains systèmes, puis on détecte les anomalies de fonctionnement.
Si cette démarche semble naturelle, elle ne fonctionne pas parfaitement. Les résultats obtenus rivalisent certes avec l’état de l’art des systèmes sans IA, mais il n’y a pas de révolution comparable à celle que l’on a pu connaître dans le domaine de la traduction ou de la reconnaissance d’images. L’intérêt des méthodes basées sur l’intelligence artificielle réside peut-être davantage dans le moindre effort qu’elles demandent pour leur mise en œuvre. Cependant, leur principal problème est celui de la « non-transférabilité » des résultats. Cela constitue un défi majeur : le bon fonctionnement en laboratoire ne garantit pas une application immédiate à d’autres cas d’étude, même légèrement différents. Cette difficulté provient du problème récurrent du manque de données de qualité pour l’apprentissage notamment, on dispose souvent de données mal étiquetées ou imparfaites. La communauté scientifique n’a pas encore trouvé de solution convaincante à ce problème, qui est l’objet d’un champ de recherche actif.
Malgré les annonces commerciales, il est en fait assez difficile de connaître précisément les mécanismes d’IA concrètement mis en œuvre dans les outils industriels de détection d’intrusions. Une migration vers l’apprentissage est certainement en cours, mais il est peu probable selon moi qu’elle améliore significativement la qualité de la détection par rapport aux méthodes actuelles, au moins dans un premier temps.
Deuxièmement, la production d’alertes nécessite comme mentionné précédemment un tri ultérieur de ces alertes, en particulier en raison du grand nombre de fausses alertes généralement produites. Dans le secteur industriel, ce tri est effectué dans des centres d’opérations de sécurité (SOC). Les techniques traditionnelles employées incluent le regroupement des alertes correspondant à un même phénomène et la détection des données aberrantes. Ici, l’apprentissage automatique peut bien sûr apporter des solutions pertinentes.
Plus généralement, en dehors du domaine de la détection, des chercheurs ont récemment configuré des routeurs réseau avec des grands modèles de langage (LLM) [routeurs], contournant ainsi la complexité de la configuration manuelle. Cette piste pourrait être explorée pour la configuration de la sécurité réseau ou des mécanismes de contrôle d’accès aux données contenues par les systèmes informatiques. On peut même envisager de dépasser l’héritage des années 70, avec une configuration par IA de droits d’accès afin d’implémenter des politiques de sécurité complexes et difficiles à mettre en œuvre aujourd’hui. Je ne développerai pas plus ici, mais l’IA pourrait ainsi contribuer à relancer des travaux sur la sécurité des systèmes d’information, sujet fondamental de la cybersécurité qui donne malheureusement lieu à très peu de recherche, en tous cas en France.
Tout ce qui précède traite de l’impact de l’IA au service de la cybersécurité. Mais l’IA va aussi avoir un impact contre la cybersécurité. En effet, les mécanismes de l’IA, et en particulier les LLM (Large Language Models), sont en capacité de générer du code et donc potentiellement du code malveillant (virus, exploitation de vulnérabilités, etc.). Ils sont aussi en mesure de rendre beaucoup plus réalistes les mails d’hameçonnage, ce qui pourrait conduire à piéger davantage d’utilisateurs. Ces effets délétères de l’IA sont encore peu observés (ou en tous cas on manque de chiffres), mais ils sont redoutés et il convient de s’y préparer, au cas où ils se concrétiseraient.
Pour terminer, on voit aussi une inquiétude marquée relative à la génération par LLM de fake news. Pour ma part, je considère que ce sujet, évidemment d’une extrême importance, ne relève pas du domaine de la cybersécurité. Pour dire les choses rapidement, tout mensonge ou toute arnaque véhiculée ou utilisant l’informatique (et qu’est-ce qui n’utilise pas l’informatique aujourd’hui ?) ne relève pas nécessairement de la cybersécurité.
À quel changement peut-on s’attendre dans le futur ? Par exemple, quelle tâche pourrait être amenée à s’automatiser, et à quels horizons ?
Comme mentionné précédemment, la supervision de sécurité sera probablement impactée par la détection d’anomalie à base d’IA, bien que des efforts restent à fournir. Il est difficile de le prédire avec précision, mais il est probable qu’un impact notable au-delà de la simple démonstration ne se produise que dans quelques années. Nous l’avons déjà abordé, l’enjeu principal réside dans la qualité des données d’apprentissage. Sans données de qualité et partageables, aucun progrès significatif ne sera possible. Des données de qualité permettront de construire des modèles de qualité, qui devront ensuite être adaptés aux cas particuliers.
Quelles connaissances en intelligence artificielle sont nécessaires pour les postes en cybersécurité ?
La sécurité combine R&D et actions opérationnelles. Les équipes opérationnelles n’ont pas nécessairement besoin de connaître le type de modèle précis à choisir ni la manière dont il est entraîné. Prenons à nouveau l’exemple de la supervision de la sécurité. Les équipes opérationnelles des SOC voient arriver des alertes et doivent être en mesure de les qualifier : fausse alerte ou alerte réelle. Pour ce travail, pas vraiment besoin d’une formation en IA radicalement différente de celle déjà au programme des formations aujourd’hui.
En revanche, en R&D, des connaissances en IA sont effectivement nécessaires. En effet, les développeurs en charge du développement des sondes de détection devront choisir des modèles, disposer d’une méthodologie solide pour l’apprentissage, ainsi que pour l’évaluation de la qualité de cet apprentissage. Une compétence solide en apprentissage automatique sera donc ici requise.
Il est également important de rappeler que les mécanismes d’apprentissage automatique sont eux-mêmes vulnérables. Il existe donc un besoin important de formation concernant les attaques spécifiques contre l’apprentissage automatique, afin d’assurer sa protection.
Que faudrait-il privilégier pour le domaine : des informaticiens à qui apprendre le métier ou des spécialistes du métier également compétents en IA ?
Je pense que nous avons besoin de spécialistes de l’IA qui s’intéressent à la sécurité, tant en termes d’utilisation de l’IA au service de la sécurité, qu’en termes d’utilisation de l’IA contre la sécurité, avec des attaques générées par IA. Il ne s’agit pas seulement de contribution à des attaques simples comme l’hameçonnage, mais aussi de génération de stratégies d’attaques sophistiquées ou de découvertes dans des logiciels de nouvelles vulnérabilités pouvant être exploitées pour réaliser des attaques, c’est à dire l’utilisation du cyberespace dans le but de perturber, de désactiver, de détruire ou de contrôler de manière malveillante un environnementou une infrastructure informatique, ou de détruire l’intégrité des données ou de voler des informations non publiques.
Les spécialistes en IA devraient être en mesure de guider les spécialistes de la sécurité, qui ne savent généralement pas quel modèle sélectionner pour quel avantage, ni à quel point telle ou telle tâche est complexe. Malheureusement, il semble que les spécialistes de l’IA, pour le moment, délaissent la sécurité de l’IA et la sécurité par l’IA, au profit de thèmes qu’ils jugent plus intéressants. J’en arrive donc à la conclusion qu’il faudra que les spécialistes en sécurité s’y attellent eux-mêmes. Comme auparavant finalement : lorsqu’ils faisaient des statistiques, ils le faisaient eux-mêmes, sans demander l’aide de mathématiciens.
Dans la continuité de mon propos, il faut que les acteurs de la R&D dans certains sous-domaines de la sécurité s’intéressent à l’usage de l’IA. Il est nécessaire que ces acteurs aient une bonne compréhension des différents mécanismes de l’IA. J’insiste aussi sur la formation spécifique sur les attaques contre l’apprentissage automatique. Je pense qu’il ne suffit pas d’étudier l’apprentissage automatique en soi, il faut aussi comprendre comment il peut être contourné.
Inversement, certains articles scientifiques (« Real Attackers Don’t Compute Gradients » [real]) expliquent clairement que les attaquants privilégient toujours les attaques les plus simples, comme l’hameçonnage. Il faut donc du discernement pour être capable d’évaluer la vraisemblance d’une attaque contre l’IA, et ces formations peuvent y contribuer.
Quelle demande formuleriez-vous auprès des concepteurs d’intelligence artificielle ?
L’histoire de l’informatique est jalonnée d’exemples où, lors de la conception d’un système, la cybersécurité est négligée. Cela s’est vérifié pour les systèmes d’exploitation, les réseaux et l’internet en particulier, et c’est le cas aujourd’hui pour l’intelligence artificielle. Or, cette négligence se révèle souvent problématique après un certain temps. Pourquoi ? Parce que réintégrer la sécurité a posteriori est extrêmement complexe, voire impossible.
Par conséquent, si j’avais un conseil à donner, ce serait d’intégrer la sécurité dès la conception, même si cela peut s’avérer parfois contraignant. Sinon, il faudra peut-être faire machine arrière, voire cela s’avérera tout simplement impossible. Réfléchissons avant d’agir !
[routeurs] Mondal, R., Tang, A., Beckett, R., Millstein, T., & Varghese, G. (2023, November). What do LLMs need to synthesize correct router configurations?. In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks (pp. 189-195).
[real] Apruzzese, G., Anderson, H. S., Dambra, S., Freeman, D., Pierazzi, F., & Roundy, K. (2023, February). “real attackers don’t compute gradients”: bridging the gap between adversarial ml research and practice. In 2023 IEEE conference on secure and trustworthy machine learning (SaTML) (pp. 339-364). IEEE.
On entend beaucoup dire que les LLM ne savent pas raisonner. Pourtant, des modèles de langage semblent capables de raisonner. Comment est-ce possible ? Pour résoudre ce mystère, nous avons demandé à un expert du domaine, Guillaume Baudart, d’expliquer à binaire ce « miracle ». Serge Abiteboul et Pierre Paradinas
Les grands modèles de langage (LLMs pour Large Language Models) sont des modèles d’intelligence artificielle capables de générer du texte en langage naturel. Entraînés sur d’immenses quantités de données, ces modèles sont au cœur d’applications comme ChatGPT (openAI) ou Le Chat (Mistral). Grâce à des développements récents, ces modèles sont de plus en plus utilisés pour des tâches allant de la génération de code à la résolution de problèmes mathématiques à partir de descriptions en langage naturel. Mais que veut dire raisonner pour ces modèles ? Peut-on se fier aux résultats ?
D’un autre côté, les assistants de preuve tels que Rocq permettent de valider une preuve mathématique avec un très haut niveau de confiance, mais l’expertise nécessaire pour utiliser ces outils les rend difficiles d’accès.
Faire communiquer efficacement un LLM et un assistant de preuve permettrait d’atteindre deux objectifs complémentaires. D’abord, l’assistant de preuve peut valider les raisonnements générés par un LLM. Ensuite, les LLMs offrent une interface conversationnelle intuitive qui peut faciliter l’utilisation de ces assistants jusque-là réservés aux experts.
Deux lois d’échelle pour les LLMs
On assiste aujourd’hui à une course mondiale pour développer des modèles de plus en plus puissants. Les chiffres donnent le tournis : les modèles les plus récents contiennent des centaines de milliards de paramètres, sont entraînés sur des milliards de textes d’origines diverses, et leur coût d’entraînement est estimé à des dizaines de millions de dollars. Pour donner un exemple récent, le modèle DeepSeek-V3 contient 671 milliards de paramètres et son entraînement a demandé près de 3 millions d’heures GPU (les processeurs graphiques utilisés pour les calculs intensifs). Si ce modèle a fait les gros titres parce que son entraînement a été incroyablement efficace pour sa taille, il aura quand même coûté environ 6 millions de dollars.
La course aux grands modèles s’explique par une observation simple : les performances augmentent avec la taille des modèles. Plus précisément, lors de l’entraînement, les paramètres (des milliards de nombres qui contrôlent le comportement du modèle) sont ajustés pour optimiser un objectif qu’on appelle la perte. Dans le cas des modèles de langage comme les LLMs, on demande au modèle de compléter un texte connu (partiellement masqué) et la perte mesure la distance entre le texte généré et le texte original. Par exemple, « Le petit chat est mort. » est très proche de « Le petit chat est fort. » mais assez loin de « Le ciel est bleu aujourd’hui. ».
Or, on a observé dès 2020 une loi d’échelle pour l’entraînement des LLMs : la perte évolue selon une loi de puissance avec la quantité de calcul (nombre de paramètres, tailles de corpus d’entraînement, et temps d’entraînement). Et plus la perte est faible, plus les modèles deviennent performants pour diverses tâches : résumer, extraire de l’information, faire des raisonnements mathématiques, générer du code informatique, etc. Il est par ailleurs possible de spécialiser les LLMs sur une tâche spécifique en complétant leur entraînement sur des données ciblées.
Beaucoup plus récemment, on a également observé une nouvelle loi d’échelle pour l’inférence : les performances d’un modèle augmentent aussi avec la taille du texte généré lors de son utilisation. Confronté à une question, les modèles récents commencent par générer un long texte appelé chaîne de pensées qui imite un comportement humain. En utilisant le contenu de la chaîne, le modèle peut ensuite synthétiser un résumé.
Des tubes de peinture contiennent 8 centilitres d’un mélange de jaune et de bleu. Il y a du bleu et du jaune dans chaque tube. Mon premier tube contient un quart de la quantité totale de jaune et un sixième de la quantité totale de bleu. Combien y a-t-il de tubes ?
Si certaines applications (comme ChatGPT) masquent les chaînes de pensées, on peut parfois demander au modèle de nous montrer tout le texte généré. Voici par exemple la chaîne de pensées générée par DeepSeek-R1 pour ce problème (attention spoiler, le raisonnement original en anglais a été traduit).
Ok, essayons de déterminer combien il y a de tubes. Le problème indique que chaque tube contient 8 centilitres d’un mélange de jaune et de bleu. Chaque tube contient les deux couleurs. Le premier tube contient un quart du total de jaune et un sixième du total de bleu. Nous devons trouver le nombre de tubes.
Hmm, décomposons le problème. Je vais noter la quantité totale de peinture jaune Y et la quantité totale de peinture bleue B. Chaque tube contient une certaine quantité de jaune et de bleu, pour un total de 8 cl. Le premier tube contient 1/4 du total de jaune et 1/6 du total de bleu. Donc, la quantité de jaune dans le premier tube est Y/4, et la quantité de bleu est B/6. Puisque chaque tube contient 8 cl au total, alors Y/4 + B/6 = 8. C’est une équation.
Maintenant, pensons aux autres tubes. Il y a n tubes au total. Chacun des (n – 1) tubes restants doit également contenir du jaune et du bleu, mais combien ? Comme le problème ne spécifie pas de distribution particulière pour les autres tubes, sauf qu’ils contiennent tous les deux couleurs, peut-être pouvons-nous supposer que le reste de jaune et de bleu est réparti équitablement entre eux ? Attendez, mais le problème ne dit pas cela. Hmm, peut-être avons-nous besoin d’une autre approche.
Alternativement, puisque le premier tube contient Y/4 de jaune et B/6 de bleu, alors la quantité restante de peinture jaune est Y – Y/4 = (3/4)Y, et la quantité restante de peinture bleue est B – B/6 = (5/6)B.
[…]
Est-ce possible ? Voyons voir. Par exemple, si nous répartissons le reste de jaune à raison de 3 cl par tube (12/4=3) et le reste de bleu à raison de 5 cl par tube (20/4=5), chaque tube contiendrait 3+5=8 cl, ce qui fonctionne. Donc oui, c’est possible. Toutes les conditions sont satisfaites si n=5. Donc, la réponse est 5 tubes.
Mais laissez-moi vérifier à nouveau. Si n=5, le volume total est de 40 cl, Y=16, B=24. Premier tube : 4 jaune, 4 bleu. Reste 12 jaune et 20 bleu. 12/4=3, 20/4=5. Chaque tube restant contient 3 jaune et 5 bleu. Cela fait 8 cl chacun, et tous contiennent les deux couleurs. Donc cela fonctionne. Par conséquent, le nombre de tubes est 5.
On peut voir le modèle essayer plusieurs approches, se corriger, vérifier ses résultats, presque comme un étudiant en train de passer un examen devant un tableau noir. Le texte est ponctué d’expressions comme : « Ok, essayons de déterminer », « peut-être pouvons-nous supposer », « Attendez », « Hmm », « Est-ce possible », « laissez-moi vérifier » qui incitent le modèle à continuer la génération de texte pour progresser dans le raisonnement. Le modèle peut ensuite synthétiser une réponse courte et structurée en résumant cette chaîne de pensées. Les LLMs les plus récents, dits modèles de raisonnement, sont spécialisés lors de l’entraînement pour générer ces chaînes de pensées.
Cette nouvelle loi d’échelle ne s’arrête pas aux chaînes de pensées. Plutôt que d’investir toute la puissance de calcul au moment de l’entraînement, on utilise maintenant les ressources de calcul pour exploiter au mieux les textes générés. Une technique simple consiste à générer plusieurs chaînes de pensées en parallèle avant de choisir celles qui ont donné les meilleurs résultats. On peut également utiliser des algorithmes de recherche arborescente : à chaque étape de raisonnement, on génère plusieurs solutions, mais on ne fait progresser que les plus prometteuses.
En combinant toutes ces approches, il est aujourd’hui possible de spécialiser de relativement petits modèles qui atteignent des performances comparables à celles des énormes LLMs les plus connus (GPT-4o, Claude Sonnet, Gemini) pour un budget beaucoup plus modeste.
Ces nouveaux développements posent une question fondamentale : comment vérifier les raisonnements produits par les LLMs ? Cette question, qui était déjà préoccupante pour les premiers LLMs, devient cruciale pour les modèles de raisonnement pour lesquels une hallucination (une information fausse et inventée) peut complètement fausser la chaîne de pensées.
On construit donc des agents : des applications capables de coupler les LLMs avec des outils externes pour valider le texte généré (par exemple pour faire des recherches sur le web, ou pour exécuter du code généré par le LLM), et des algorithmes de recherche.
Généré par Théo Stoskopf à l’aide de ChatGPT. L’oiseau est inspiré du logo de l’assistant Rocq.
Valider les chaînes de pensées avec un assistant de preuve
Fruit d’un travail à l’intersection de la logique mathématique et la théorie des langages de programmation, les assistants de preuve sont des outils qui permettent à un ordinateur de vérifier un raisonnement mathématique. Une preuve est décomposée en étapes logiques et l’ordinateur vérifie que chaque étape respecte les règles de la logique mathématique. Si une preuve repose sur l’utilisation d’un théorème, l’ordinateur vérifie que toutes les hypothèses sont bien vérifiées et que la conclusion suffit à prouver le résultat attendu
Les assistants de preuve comme Rocq (anciennement Coq), Lean ou Isabelle sont des outils interactifs. L’utilisateur propose une étape de raisonnement que l’ordinateur vérifie avant d’indiquer à l’utilisateur ce qu’il reste à démontrer. Prenons un exemple très classique :
Tous les hommes sont mortels. Socrate est un homme. Donc, Socrate est mortel.
Le but initial est de prouver Socrate est mortel. Pour prouver ce théorème, on peut commencer par spécialiser la première prémisse Tous les hommes sont mortels à l’individu Socrate. L’assistant ajoute alors une nouvelle hypothèse : Si Socrate est un homme alors Socrate est mortel. On applique alors la seconde prémisse Socrate est un homme à cette hypothèse et l’assistant vérifie qu’on obtient bien Socrate est mortel.
Buste d’origine romaine en marbre de Socrate, Le Louvres
En théorie, ce fonctionnement interactif est parfaitement adapté pour développer un agent capable de vérifier un raisonnement mathématique. Chaque étape de raisonnement est validée par l’assistant de preuve, et les réponses (ou les messages d’erreur) de l’assistant de preuve nourrissent le LLM pour générer les prochaines étapes de raisonnement. Malheureusement, cet exercice de formalisation reste particulièrement difficile pour les humains comme pour les LLMs. Des LLMs récents sont aujourd’hui très performants pour la génération de code, mais l’exercice de preuve formelle ajoute une contrainte fondamentale qui rend l’exercice beaucoup plus compliqué : la preuve n’est terminée que si le code est parfaitement correct. Il n’y a aucune approximation possible. Par ailleurs, le code doit être écrit dans un langage spécialisé dont il existe relativement peu d’exemples au milieu des immenses quantités de données utilisées lors de l’entraînement.
Pour utiliser au mieux les capacités des LLMs, on peut réutiliser l’idée des chaînes de pensées. Plutôt que d’essayer de générer directement du code, on demande au modèle de décrire le théorème et ses hypothèses en langage naturel (par exemple en anglais ou français) et de suggérer un schéma de preuve, avant de générer le code en résumant la chaîne de pensées.
Couplé avec des algorithmes de recherche, cette approche commence à donner des résultats impressionnants sur des exercices de niveau lycée ou licence [1-2-3]. En utilisant une technique d’apprentissage « par renforcement » AlphaProof, un modèle entraîné par Google Deepmind sur des millions de théorèmes générés automatiquement, a même réussi à prouver avec l’assistant de preuve Lean des problèmes d’olympiades de mathématiques, atteignant le niveau d’une médaille d’argent.
Un assistant d’assistant de preuve
Les assistants de preuve sont donc des outils précieux pour valider les raisonnements générés par les LLMs. En changeant de perspectives, les LLMs peuvent également modifier en profondeur la manière dont nous utilisons des assistants de preuves qui restent aujourd’hui des outils réservés aux experts.
Si le code final doit être écrit dans un langage de programmation spécialisé, les chaînes de pensées générées lors du raisonnement sont écrites en langage naturel. Un humain peut donc facilement inspecter le raisonnement pour comprendre le code suggéré par l’assistant, voire directement intervenir pour le corriger. Les LLMs permettent ainsi de développer des interfaces conversationnelles : il devient de plus en plus possible de « discuter » (en français ou en anglais) avec l’assistant de preuve pour formaliser un théorème sans être un expert du langage de programmation spécialisé.
Les logiciels d’édition de code intègrent déjà ce genre de technologies pour les langages les plus populaires comme Python ou JavaScript. Ces assistants rendent de nombreux services qui vont de l’autocomplétion (compléter un bout de code à partir du contexte et des commentaires) à l’analyse de documentation (par exemple pour retrouver une fonction ou un théorème à partir d’une description floue en langage naturel).
L’utilisation des LLMs pour les assistants de preuve est un domaine de recherche aujourd’hui très actif. On cherche à développer des agents capables de faciliter de nombreuses tâches qui restent difficiles ou ingrates pour les humains. Par exemple, en utilisant les impressionnantes capacités de traduction des LLMs, on aimerait traduire directement un livre de mathématiques (théorèmes et preuves) dans le langage de l’assistant de preuve. Cette tâche suppose d’être capable de comprendre le contexte, les hypothèses implicites propres à chaque domaine, et la nature des objets mathématiques manipulés. Les LLMs récents entraînés sur de très nombreux textes mathématiques (avec différents niveaux de rigueur) peuvent faire des associations d’idées pour combler les « trous » entre le langage naturel du livre et sa formalisation dans un assistant de preuve. Ce problème reste très difficile, mais une solution partielle générée par un LLM peut être un point de départ précieux pour un humain.
Enfin, le comportement d’un programme peut aussi être formalisé dans un assistant de preuve. Il est donc possible de prouver qu’un programme est correct. Par exemple, on peut prouver qu’une fonction de tri en Python ou JavaScript renvoie toujours un tableau trié. À plus long terme, on aimerait avoir des assistants capables de traduire une spécification en langage naturel vers un code exécutable, une formalisation de la spécification, et une preuve de correction qui montre que le code correspond bien à sa spécification. Les assistants de preuve aidés par des LLMs permettraient ainsi de garantir que le code généré par un LLM est bien correct ! C’est un enjeu crucial dans un monde où le code informatique des applications que nous utilisons tous les jours devient de plus en plus généré automatiquement par ces modèles.
Conclusion
Faire communiquer LLMs et assistants de preuve ouvre des perspectives prometteuses pour l’avenir de l’intelligence artificielle et de la vérification formelle. En combinant la capacité des LLMs à générer des raisonnements complexes en langage naturel avec la rigueur des assistants de preuve, il devient possible de développer des agents capables de vérifier des preuves mathématiques. Ces agents pourraient non seulement améliorer la fiabilité des résultats produits par les LLMs et les capacités de raisonnement des futures générations de modèles, mais aussi rendre les outils de preuve formelle aujourd’hui réservés à des experts plus accessibles.
Guillaume Baudart, Inria
[1] https://arxiv.org/abs/2310.04353
[2] https://hal.science/hal-04886208v1
[3] https://arxiv.org/abs/2408.08152
Note : Merci à Vincent Baudart, Paul-André Melliès, Marc Lelarge, Théo Stoskopf, Jules Viennot, et Sarah Winter pour leurs relectures et leurs suggestions.
L’article « Revelations: A Decidable Class of POMDP with Omega-Regular Objectives » a été primé par le « Outstanding Paper Award » à la conférence AAAI 2025, la plus prestigieuse conférence internationale en intelligence artificielle (https://aaai.org/). Cette récompense couronne le fruit d’un travail de recherche initié à Bordeaux, au sein de l’équipe Synthèse (https://synth.labri.fr/) du Laboratoire Bordelais de Recherche en Informatique (LaBRI), où travaillent quatre des auteurs: Marius Belly, Nathanaël Fijalkow, Hugo Gimbert et Pierre Vandenhove, en coopération avec des chercheurs à Paris (Florian Horn) et Anvers (Guillermo Pérez). Après nous avoir raconté la genèse de ce papier dans un précédent article, ce billet en esquisse les idées principales, tandis que l’article complet est consultable librement à l’adresse https://arxiv.org/abs/2412.12063 . Chloé Mercier et Serge Abiteboul.
L’équipe Synthèse du LaBRI s’attaque au problème ardu de la synthèse de programme. Il s’agit de développer des algorithmes qui eux-mêmes génèrent d’autres algorithmes, à partir de quelques exemples ou d’une spécification de ce qui est attendu. Concrètement, ces algorithmes très puissants sont utilisés dans une variété de contextes. Par exemple, la plupart des tableurs proposent aujourd’hui des fonctions de remplissage automatique : vous remplissez quelques cellules et, à partir de ces quelques exemples, un petit algorithme est synthétisé à la volée et se charge de finir le travail (https://deepsynth.labri.fr/). Un autre exemple est le contrôle robotique : un opérateur transmet à un robot une tâche à exécuter, par exemple reprendre le contrôle de la balle dans un match de Robocup, et charge au robot et à ses algorithmes de programmer la bonne suite de mouvements et d’actions à effectuer pour arriver au but escompté.
Quand les ingénieurs et chercheurs en Intelligence Artificielle (IA) ont besoin de résoudre des problèmes de synthèse, ils utilisent couramment un formalisme mathématique appelé processus de décision Markoviens, ou pour faire plus court, les MDP. La question centrale est la suivante : dans une situation où il faut prendre une suite de décisions, décrite par un MDP, comment faire pour prendre de bonnes décisions ? Ou, encore mieux, comment faire pour calculer automatiquement la meilleure suite de décisions possibles, ce qui s’appelle également une stratégie optimale ?
Les MDP pour décider
Mais qu’est-ce qu’un MDP exactement ? Dans le contexte de cette recherche, c’est un système à états finis dont l’évolution est déterminée à la fois par les décisions (choix d’action), mais également par le hasard. Voilà à quoi ressemble un tel animal :
Ce MDP illustre un exemple issu de l’article. C’est un jeu classique : il y a deux portes, et un tigre se cache derrière l’une des deux. On doit choisir quelle porte ouvrir, mais on ne sait pas où est le tigre. Grâce à l’action “écouter” (“listen” dans l’illustration) on peut révéler où se cache le tigre avec une probabilité positive. Crédits: les auteurs.
Dans la vie courante, on peut se servir des MDP à de multiples occasions (nous les avions déjà rencontré dans le cas du Cluedo dans un autre article binaire), par exemple pour jouer au « Solitaire », également appelé « Patience » ou encore « Spider Solitaire » dans sa célèbre variante. La situation ci-dessous illustre le dilemme de la prise de décision dans un MDP : faut-il placer un des deux rois noirs sur la pile vide à gauche ? Si oui, lequel des deux ? Le choix est épineux car certaines cartes sont masquées et ne seront révélées qu’ultérieurement.
Le jeu de Solitaire. Même quand toutes les cartes sont révélées, le problème est difficile : cf https://web.stanford.edu/~bvr/pubs/solitaire.pdf. Crédits: les auteurs.
Stratégies de résolution des MDP
Il y a deux grandes catégories d’algorithmes IA pour résoudre un MDP, qui peuvent paraître similaires à première vue mais qui pour les chercheurs en informatique sont bien distinctes. D’une part, il y a les algorithmes qui fonctionnent bien en pratique mais sans garantie de fournir la meilleure solution, ce qui est le cas de la plupart des méthodes d’apprentissage, notamment celles utilisant les réseaux de neurones (DeepRL). D’autre part, il y a les algorithmes qui fournissent à coup sûr une réponse exacte, qui relèvent de l’IA de confiance, basée sur la notion de calculabilité et de problème décidable développé par le génie Alan Turing, pionnier de l’informatique théorique. L’article des chercheurs bordelais appartient à la seconde catégorie : quand l’algorithme proposé produit une stratégie gagnante, on peut utiliser cette stratégie en toute confiance — elle garantit de gagner avec probabilité 1.
Soyons modestes et réalistes : les techniques d’apprentissage permettent de calculer des stratégies dans des problèmes très complexes alors que les techniques exactes au sens de la théorie de la calculabilité sont pour l’instant circonscrites à des problèmes plus simples, car elles sont en général beaucoup plus gourmandes en ressources de calcul. Par exemple, Google DeepMind a exploité les techniques de DeepRL afin de synthétiser d’excellentes stratégies à StarCraft, un jeu vidéo populaire dans lequel il faut prendre des dizaines de décisions par seconde en fonction de millions de paramètres. L’IA de DeepMind a initialement battu les meilleurs joueurs mondiaux, mais sa stratégie n’était pas parfaite : des contre-stratégies difficilement prévisibles ont ensuite été découvertes. Les méthodes exactes sont aujourd’hui inexploitables pour résoudre un problème aussi complexe que StarCraft, mais cela ne les empêche pas d’être efficaces en pratique. Par exemple, autre succès bordelais, l’équipe Rhoban du LaBRI a remporté une médaille d’or à la Robocup 2023 en exploitant des méthodes exactes pour résoudre de petits MDP en se basant sur le partage d’informations entre plusieurs robots coopératifs (https://github.com/Rhoban/TeamPlay).
La difficulté de la résolution exacte de problèmes de décision est très variable en fonction de l’information disponible au moment de la décision. Le cas idéal est celui de l’information parfaite, c’est le cas où toute l’information est disponible. Un exemple classique est celui d’un robot qui doit sortir d’un labyrinthe dont on connaît le plan ainsi que la propre position et orientation exacte du robot. Dans ce cas, le calcul est relativement facile à effectuer : il faut calculer un chemin vers la sortie (par exemple avec l’algorithme de Dijkstra) puis suivre ce chemin avec la suite de commandes de déplacement adéquates. Mais dans les problèmes rencontrés en pratique, il est rare d’avoir toutes les cartes en main. C’est le cas au solitaire, où une partie des cartes est masquée, ce qui nécessite de faire des hypothèses. Dans ce cas, en toute généralité le problème ne peut être résolu de manière exacte, la réponse n’est pas calculable au sens de Turing : aucun algorithme, aussi puissant que soit l’ordinateur sur lequel il est programmé, ne peut résoudre avec exactitude tous les problèmes de contrôle de MDP. C’est assez démoralisant à première vue pour un informaticien mais cela n’arrête pas certains chercheurs en informatique qui s’attellent à trouver des classes de MDP pour lesquelles le problème est moins complexe. En informatique théorique, on appelle cela une classe décidable.
Le travail de recherche primé à AAAI fournit justement une classe décidable de MDP : c’est le cas des problèmes avec « révélation forte », pour lesquels à chaque instant il y a une probabilité non-nulle que l’état exact du monde soit révélé. L’article donne aussi des résultats de décidabilité pour le cas des « révélations faibles », qui garantit que l’état exact du monde ne peut rester inconnu infiniment longtemps.
Un article de recherche se doit d’être tourné vers le futur, d’ouvrir des pistes. Notre algorithme permet d’analyser les jeux avec des révélations (fortes). Une perspective intéressante est de retourner le problème : on peut se demander plus généralement ce que fait l’algorithme lorsqu’il est utilisé pour n’importe quel jeu, avec ou sans révélations. Cela permet d’envisager d’analyser tous les jeux, même les plus compliqués, mais en restreignant plutôt le type de stratégie que les joueurs utilisent, ou la quantité d’informations qu’ils sont capables de traiter.
Marius Belly, Nathanaël Fijalkow, Hugo Gimbert, Florian Horn, Guillermo A. Pérez et Pierre Vandenhove
Les chercheurs ont toujours du mal à expliquer comment la recherche progresse dans un cadre international, pluridisciplinaire et collaboratif. Nous allons illustrer cela avec la genèse d’un article scientifique « Revelations: A Decidable Class of POMDP with Omega-Regular Objectives ». Cet article a été primé par le « Outstanding Paper Award » à la conférence AAAI 2025, la plus prestigieuse conférence internationale en intelligence artificielle (https://aaai.org/). Quatre des auteurs, Marius Belly, Nathanaël Fijalkow, Hugo Gimbert et Pierre Vandenhove, sont au laboratoire bordelais de recherche en informatique (LaBRI). Ils ont collaboré avec des chercheurs à Paris (Florian Horn) et Anvers (Guillermo Pérez). L’article est consultable librement à l’adresse https://arxiv.org/abs/2412.12063. Les auteurs racontent ici pour binaire l’histoire de ce travail. L’intérêt de l’article est d’observer la recherche en train de se faire. Il n’est pas nécessaire de comprendre même leurs résultats. Dans un second article, ils donneront plus de détails sur les contributions scientifiques. Serge Abiteboul et Chloé Mercier.
La question originale a été posée pendant le workshop « Gamenet » sur la théorie des jeux mêlant informaticiens, mathématiciens et économistes à Maastricht (Pays-Bas) en 2022. Les résultats mathématiques présentés par Guillaume Vigeral et Bruno Ziliotto sur les phénomènes de “révélations” dans les modèles de jeux à information imparfaite ont suscité la curiosité de Hugo et Florian au sujet des propriétés algorithmiques de ces jeux.
Le poker est un exemple classique de jeu à information imparfaite : chaque joueur possède à tout moment une information partielle de la partie, à savoir il connaît sa main et ce que les autres joueurs ont annoncé, mais pas la main des autres joueurs. Les jeux à information imparfaite sont extrêmement durs à comprendre d’un point de vue algorithmique, et l’on peut même prouver que, dans des modèles très simples, ils sont “indécidables”, ce qui signifie qu’il n’existe pas d’algorithme permettant de construire une stratégie optimale. Analyser algorithmiquement les jeux à information imparfaite est un vaste programme de recherche, très actif dans le monde académique mais également dans l’industrie : Google DeepMind s’est par exemple attaqué à StarCraft. Son succès a été mitigé puisque, si l’IA a initialement battu les meilleurs joueurs mondiaux, des stratégies imprévisibles contrant l’IA ont ensuite été découvertes.
Informellement, une “révélation” dans un jeu à information imparfaite correspond à un instant où les joueurs possèdent une connaissance complète de l’état du jeu. Par exemple au poker, lorsque tous les joueurs révèlent leurs cartes. Mais le mécanisme du jeu peut introduire après ce moment à nouveau des incertitudes, par exemple si un joueur pioche une nouvelle carte et ne la révèle pas. A son retour à Bordeaux, Hugo a posé à Nathanaël cette question fascinante : les jeux qui impliquent “régulièrement” des révélations sont-ils plus faciles à analyser d’un point de vue algorithmique ? Intuitivement, la difficulté d’analyser les jeux à information imparfaite est due à la multiplication des possibilités. Mais s’il y a “souvent” des révélations, ce nombre de possibilités devrait être réduit. Nous avons commencé à plancher sur ce sujet à trois : Nathanaël, Hugo, et Florian.
Hugo et Florian ont rendu visite à Nathanaël pendant son année sabbatique à l’Université de Varsovie (en 2023), et l’hiver polonais leur a permis de faire une première découverte : ils ont prouvé que ces jeux n’étaient pas plus faciles à analyser que le cas général. Au lieu d’abandonner, ils ont décidé de se focaliser sur les processus de décisions Markoviens (MDP), cas particulier des jeux où il n’y a qu’un seul joueur. Dans ce nouveau cadre, ils ont formulé des conjectures et conçu un algorithme pour résoudre ces MDP, mais ils n’avaient pas encore de preuve complète.
Encouragé par ces résultats, Hugo a proposé à Marius, alors étudiant en Master, d’effectuer son stage de recherche sur cette question au printemps 2023. Après de longs mois à manipuler des outils probabilistes et topologiques et après deux visites à Paris pour travailler avec Florian, les premières preuves ont été couchées sur papier. Le stage a en particulier permis de formaliser une distinction importante : il a distingué entre deux notions différentes de “révélations”, dites “faible” et “forte”. Malgré les progrès, de nombreuses questions restaient ouvertes.
Pierre a alors commencé un post-doctorat dans l’équipe bordelaise en septembre 2023, peu après la fin du stage de Marius. Il a dévoré son rapport de stage, relançant encore une fois la machine : l’espoir fait vivre et nourrit la recherche. Nous avons alors fait de grands pas en avant, et obtenu des résultats positifs dans le cas de révélations fortes ainsi que des résultats négatifs pour les révélations faibles. Plus précisément, nous avons construit un algorithme permettant d’analyser les jeux avec des révélations fortes, et montré que cela était impossible (indécidable) en cas de révélations faibles. C’est aussi une expérience classique en recherche : lorsque l’on se lance dans un nouveau problème, on commence par faire de tout petits pas. Plus on avance dans la compréhension des objets, et plus on fait de grands pas, jusqu’à résoudre le problème (ou pas). Faire de la recherche, c’est ré-apprendre à marcher à chaque nouveau problème !
Pour valider nos résultats empiriquement, nous avons collaboré avec Guillermo, expert des méthodes statistiques et exactes pour les jeux stochastiques. L’intérêt de l’algorithme que nous avions construit était d’être conceptuellement très simple et facile à implémenter. Il s’est avéré qu’il permet également en pratique de construire des stratégies plus performantes !
Un article de recherche se doit d’être tourné vers le futur, d’ouvrir des pistes. Notre algorithme permet d’analyser les jeux avec des révélations (fortes). Une perspective intéressante est de retourner le problème : on peut se demander plus généralement ce que fait l’algorithme lorsqu’il est utilisé pour n’importe quel jeu, avec ou sans révélations. Cela permet d’envisager d’analyser tous les jeux, même les plus compliqués, mais en restreignant plutôt le type de stratégie que les joueurs utilisent, ou la quantité d’informations qu’ils sont capables de traiter.
Marius Belly, Nathanaël Fijalkow, Hugo Gimbert, Florian Horn, Guillermo A. Pérez et Pierre Vandenhove
Un nouvel entretien autour de l’informatique. Michel Beaudouin-Lafon est un chercheur en informatique français dans le domaine de l’interaction humain-machine. Il est professeur depuis 1992 à l’université de Paris-Saclay. Ses travaux de recherche portent sur les aspects fondamentaux de l’interaction humain-machine, l’ingénierie des systèmes interactifs, le travail collaboratif assisté par ordinateur et plus généralement les nouvelles techniques d’interaction. Il a co-fondé et a été premier président de l’Association francophone pour l’interaction humain-machine. Il est membre senior de l’Institut universitaire de France, lauréat de la médaille d’argent du CNRS, ACM Fellow, et depuis 2025 membre de l’Académie des sciences. Cet article est publié en collaboration avec The Conversation.
Michel Beaudouin-Lafon, https://www.lri.fr/~mbl/
Binaire : Pourrais-tu nous raconter comment tu es devenu un spécialiste de l’interaction humain-machine ?
MBL : J’ai suivi les classes préparatoires au lycée Montaigne à Bordeaux. On n’y faisait pas d’informatique, mais je m’amusais déjà un peu avec ma calculatrice programmable HP29C. Ensuite, je me suis retrouvé à l’ENSEEIHT, une école d’ingénieur à Toulouse, où j’ai découvert l’informatique… un peu trop ardemment : en un mois, j’avais épuisé mon quota de calcul sur les cartes perforées !
À la sortie, je n’étais pas emballé par l’idée de rejoindre une grande entreprise ou une société de service. J’ai alors rencontré Gérard Guiho de l’université Paris-Sud (aujourd’hui Paris-Saclay) qui m’a proposé une thèse en informatique. Je ne savais pas ce que c’était qu’une thèse : nos profs à l’ENSEEIHT, qui étaient pourtant enseignants-chercheurs, ne nous parlaient jamais de recherche.
CPN Tools (https://cpntools.org)
Fin 1982, c’était avant le Macintosh, Gérard venait d’acquérir une station graphique dont personne n’avait l’usage dans son équipe. Il m’a proposé de travailler dessus. Je me suis bien amusé et j’ai réalisé un logiciel d’édition qui permettait de créer et simuler des réseaux de Pétri, un formalisme avec des ronds, des carrés, des flèches, qui se prêtait bien à une interface graphique. C’est comme ça que je me suis retrouvé à faire une thèse en IHM : interaction humain-machine.
Binaire : Est-ce que l’IHM existait déjà comme discipline à cette époque ?
MBL : Ça existait mais de manière encore assez confidentielle. La première édition de la principale conférence internationale dans ce domaine, Computer Human Interaction (CHI), a eu lieu en 1982. En France, on s’intéressait plutôt à l’ergonomie. Une des rares exceptions : Joëlle Coutaz qui, après avoir découvert l’IHM à CMU (Pittsburgh), a lancé ce domaine à Grenoble.
Binaire : Et après la thèse, qu’es-tu devenu ?
MBL : J’ai été nommé assistant au LRI, le laboratoire de recherche de l’Université Paris-Sud, avant même d’avoir fini ma thèse. Une autre époque ! Finalement, j’ai fait toute ma carrière dans ce même laboratoire, même s’il a changé de nom récemment pour devenir le LISN, laboratoire interdisciplinaire des sciences du numérique. J’y ai été nommé professeur en 1992. J’ai tout de même bougé un peu. D’abord en année sabbatique en 1992 à l’Université de Toronto, puis en détachement à l’Université d’Aarhus au Danemark entre 1998 et 2000, et enfin plus récemment comme professeur invité à l’université de Stanford entre 2010 et 2012.
En 1992, au cours d’un workshop au Danemark, j’ai rencontré Wendy Mackay, une chercheuse qui travaillait sur l’innovation par les utilisateurs. Un an plus tard, nous étions mariés ! Cette rencontre a été déterminante dans ma carrière pour combiner mon parcours d’ingénieur, que je revendique toujours, avec son parcours à elle, qui était psychologue. Wendy est spécialiste de ce qu’on appelle la conception participative, c’est-à-dire d’impliquer les utilisateurs dans tout le cycle de conception des systèmes interactifs. Je vous invite d’ailleurs à lire son entretien dans Binaire. C’est cette complémentarité entre nous qui fait que notre collaboration a été extrêmement fructueuse sur le plan professionnel. En effet, dans le domaine de l’IHM, c’est extrêmement important d’allier trois piliers : (1) l’aspect humain, donc la psychologie ; (2) le design, la conception, la créativité ; et (3) l’ingénierie. Ce dernier point concerne la mise en œuvre concrète, et les tests avec des vrais utilisateurs pour voir si ça marche (ou pas) comme on l’espère. Nous avons vécu la belle aventure du développement de l’IHM en France, et sa reconnaissance comme science confirmée, par exemple, avec mon élection récente à l’Académie des Sciences.
Binaire : L’IHM est donc une science, mais en quoi consiste la recherche dans ce domaine ?
MBL : On nous pose souvent la question. Elle est légitime. En fait, on a l’impression que les interfaces graphiques utilisées aujourd’hui par des milliards de personnes ont été inventées par Apple, Google ou Microsoft, mais pas vraiment ! Elles sont issues de la recherche académique en IHM !
Si on définit souvent l’IHM par Interface Humain-Machine, je préfère parler d’Interaction Humain-Machine. L’interaction, c’est le phénomène qui se produit lorsqu’on est utilisateur d’un système informatique et qu’on essaie de faire quelque chose avec la machine, par la machine. On a ainsi deux entités très différentes l’une de l’autre qui communiquent : d’un côté, un être humain avec ses capacités cognitives et des moyens d’expression très riches ; et de l’autre, des ordinateurs qui sont de plus en plus puissants et très rapides mais finalement assez bêtes. Le canal de communication entre les deux est extrêmement ténu : taper sur un clavier, bouger une souris. En comparaison des capacités des deux parties, c’est quand même limité. On va donc essayer d’exploiter d’autres modalités sensorielles, des interfaces vocales, tactiles, etc., pour multiplier les canaux, mais on va aussi essayer de rendre ces canaux plus efficaces et plus puissants.
Ce phénomène de l’interaction, c’est un peu une sorte de matière noire : on sait que c’est là, mais on ne peut pas vraiment la voir. On ne peut la mesurer et l’observer que par ses effets sur la machine et sur l’être humain. Et donc, on observe comment l’humain avec la machine peuvent faire plus que l’humain seul et la machine seule. C’est une idée assez ancienne : Doug Engelbart en parlait déjà dans les années 60 (voir dans Interstices). Et pourtant, aujourd’hui, on a un peu tendance à l’oublier car on se focalise sur des interfaces de plus en plus simples, où c’est la machine qui va tout faire et on n’a plus besoin d’interagir. Or, je pense qu’il y a vraiment une valeur ajoutée à comprendre ce phénomène d’interaction pour en tirer parti et faire que la machine augmente nos capacités plutôt que faire le travail à notre place. Par extension, on s’intéresse aussi à ce que des groupes d’humains et de machines peuvent faire ensemble.
Les théories génératives d’interaction (Beaudouin-Lafon, Bødker et Mackay, 2021)
La recherche en IHM, il y a donc un aspect recherche fondamentale qui se base sur d’autres domaines (la psychologie mais aussi la sociologie quand on parle des interactions de groupes, ou encore la linguistique dans le cadre des interactions langagières) qui permet de créer nos propres modèles d’interaction, qui ne sont pas des modèles mathématiques ; et ça, je le revendique parce que je pense que c’est une bonne chose qu’on ne sache pas encore mettre le cerveau humain en équation. Et puis il y a une dimension plus appliquée où on va créer des objets logiciels ou matériels pour mettre tout ça en œuvre.
Pour moi, l’IHM ne se résume pas à faire de nouveaux algorithmes. Au début des années 90, Peter Wegener a publié dans Communications of the ACM – un des journaux de référence dans notre domaine – un article qui disait “l’interaction est plus puissante que les algorithmes”. Cela lui a valu pas mal de commentaires et de critiques, mais ça m’a beaucoup marqué.
Binaire : Et à propos d’algorithmes, est-ce que l’IA soulève de nouvelles problématiques en IHM ?
MBL : Oui, absolument ! En ce moment, les grandes conférences du domaine débordent d’articles qui combinent des modèles de langage (LLM) ou d’autres techniques d’IA avec de l’IHM.
Historiquement, dans une première phase, l’IA a été extrêmement utilisée en IHM, par exemple pour faire de la reconnaissance de gestes. C’était un outil commode, qui nous a simplifié la vie, mais sans changer nos méthodes d’interaction.
Aux débuts de l’IA générative, on est un peu revenu 50 ans en arrière en matière d’interaction, quand la seule façon d’interagir avec les ordinateurs, c’était d’utiliser le terminal. On fait un prompt, on attend quelques secondes, on a une réponse ; ça ne va pas, on bricole. C’est une forme d’interaction extrêmement pauvre. De plus en plus de travaux très intéressants imaginent des interfaces beaucoup plus interactives, où on ne voit plus les prompts, mais où on peut par exemple dessiner, transformer une image interactivement, sachant que derrière, ce sont les mêmes algorithmes d’IA générative avec leurs interfaces traditionnelles qui sont utilisés.
Pour moi, l’IA soulève également une grande question : qu’est-ce qu’on veut déléguer à la machine et qu’est-ce qui reste du côté humain ? On n’a pas encore vraiment une bonne réponse à ça. D’ailleurs, je n’aime pas trop le terme d’intelligence artificielle. Je n’aime pas attribuer des termes anthropomorphiques à des systèmes informatiques. Je m’intéresse plutôt à l’intelligence augmentée, quand la machine augmente l’intelligence humaine. Je préfère mettre l’accent sur l’exploitation de capacités propres à l’ordinateur, plutôt que d’essayer de rendre l’ordinateur identique à un être humain.
Binaire : La parole nous permet d’interagir avec les autres humains, et de la même façon avec des bots. N’est-ce pas plus simple que de chercher la bonne icône ?
MBL : Interagir par le langage, oui, c’est commode. Ceci étant, à chaque fois qu’on a annoncé une nouvelle forme d’interface qui allait rendre ces interfaces graphiques (avec des icônes, etc.) obsolètes, cela ne s’est pas vérifié. Il faut plutôt s’intéresser à comment on fait cohabiter ces différentes formes d’interactions. Si je veux faire un schéma ou un diagramme, je préfère le dessiner plutôt que d’imaginer comment le décrire oralement à un système qui va le faire (sans doute mal) pour moi. Ensuite, il y a toujours des ambiguïtés dans le langage naturel entre êtres humains. On ne se contente pas des mots. On les accompagne d’expressions faciales, de gestes, et puis de toute la connaissance d’un contexte qu’un système d’IA aujourd’hui n’a souvent pas, ce qui le conduit à faire des erreurs que des humains ne feraient pas. Et finalement, on devient des correcteurs de ce que fait le système, au lieu d’être les acteurs principaux.
Ces technologies d’interaction par la langue naturelle, qu’elles soient écrites ou orales, et même si on y combine des gestes, soulèvent un sérieux problème : comment faire pour que l’humain ne se retrouve pas dans une situation d’être de plus en plus passif ? En anglais, on appelle ça de-skilling : la perte de compétences et d’expertise. C’est un vrai problème parce que, par exemple, quand on va utiliser ces technologies pour faire du diagnostic médical, ou bien prononcer des sentences dans le domaine juridique, on va mettre l’être humain dans une situation de devoir valider ou non la décision posée par une IA. Et en fait, il va être quand même encouragé à dire oui, parce que contredire l’IA revient à s’exposer à une plus grande responsabilité que de constater a posteriori que l’IA s’est trompée. Donc dans ce genre de situation, on va chercher comment maintenir l’expertise de l’utilisateur et même d’aller vers de l’upskilling, c’est-à-dire comment faire pour qu’un système d’IA le rende encore plus expert de ce qu’il sait déjà bien faire, plutôt que de déléguer et rendre l’utilisateur passif. On n’a pas encore trouvé la façon magique de faire ça. Mais si on reprend l’exemple du diagnostic médical, si on demande à l’humain de faire un premier diagnostic, puis à l’IA de donner le sien, et que les deux ont ensuite un échange, c’est une interaction très différente que d’attendre simplement ce qui sort de la machine et dire oui ou non.
Binaire : Vous cherchez donc de nouvelles façons d’interagir avec les logiciels, qui rendent l’humain plus actif et tendent vers l’upskilling.
MBL : Voilà ! Notre équipe s’appelle « Ex Situ », pour Extreme Situated Interaction. C’est parti d’un gag parce qu’avant, on s’appelait « In Situ » pour Interaction Située. Il s’agissait alors de concevoir des interfaces en fonction de leur contexte, de la situation dans laquelle elles sont utilisées.
Nous nous sommes rendus compte que nos recherches conduisaient à nous intéresser à ce qu’on a appelé des utilisateurs “extrêmes”, qui poussent la technologie dans ses retranchements. En particulier, on s’intéresse à deux types de sujets, qui sont finalement assez similaires. D’un part, les créatifs (musiciens, photographes, graphistes…) qui par nature, s’ils ont un outil (logiciel ou non) entre les mains, vont l’utiliser d’une manière qui n’était pas prévue, et ça nous intéresse justement de voir comment ils détournent ces outils. D’autre part, Wendy travaille, depuis longtemps d’ailleurs, dans le domaine des systèmes critiques dans lequel on n’a pas droit à l’erreur : pilotes d’avion, médecins, etc.
Dans les industries culturelles et créatives (édition, création graphique, musicale, etc.), les gens sont soit terrorisés, soit anxieux, de ce que va faire l’IA. Et nous, ce qu’on dit, c’est qu’il ne s’agit pas d’être contre l’IA – c’est un combat perdu de toute façon – mais de se demander comment ces systèmes vont pouvoir être utilisés d’une manière qui va rendre les humains encore plus créatifs. Les créateurs n’ont pas besoin qu’on crée à leur place, ils ont besoin d’outils qui les stimulent. Dans le domaine créatif, les IA génératives sont, d’une certaine façon, plus intéressantes quand elles hallucinent ou qu’elles font un peu n’importe quoi. Ce n’est pas gênant au contraire.
Binaire : L’idée d’utiliser les outils de façon créative, est-ce que cela conduit au design ?
MBL : Effectivement. Par rapport à l’ergonomie, qui procède plutôt selon une approche normative en partant des tâches à optimiser, le design est une approche créative qui questionne aussi les tâches à effectuer. Un designer va autant mettre en question le problème, le redéfinir, que le résoudre. Et pour redéfinir le problème, il va interroger et observer les utilisateurs pour imaginer des solutions. C’est le principe de conception participative, qui implique les acteurs eux-mêmes en les laissant s’approprier leur activité, ce qui donne finalement de meilleurs résultats, non seulement sur le plan de la performance mais aussi et surtout sur l’acceptation.
Notre capacité naturelle d’être humain nous conduit à constamment réinventer notre activité. Lorsque nous interagissons avec le monde, certes nous utilisons le langage, nous parlons, mais nous faisons aussi des mouvements, nous agissons sur notre environnement physique ; et ça passe parfois par la main nue, mais surtout par des outils. L’être humain est un inventeur d’outils incroyables. Je suis passionné par la facilité que nous avons à nous servir d’outils et à détourner des objets comme outils ; qui n’a pas essayé de défaire une vis avec un couteau quand il n’a pas de tournevis à portée de main ? Et en fait, cette capacité spontanée disparaît complètement quand on passe dans le monde numérique. Pourquoi ? Parce que dans le monde physique, on utilise des connaissances techniques, on sait qu’un couteau et un tournevis ont des propriétés similaires pour cette tâche. Alors que dans un environnement numérique, on a besoin de connaissances procédurales : on apprend que pour un logiciel il faut cliquer ici et là, et puis dans un autre logiciel pour faire la même chose, c’est différent.
Le concept d’interaction instrumentale (illustration par Nicolas Taffin)
C’est en partant de cette observation que j’ai proposé l’ERC One, puis le projet Proof-of Concept OnePub, qui pourrait peut-être même déboucher sur une startup. On a voulu fonder l’interaction avec nos ordinateurs d’aujourd’hui sur ce modèle d’outils – que j’appelle plutôt des instruments, parce que j’aime bien l’analogie avec l’instrument de musique et le fait de devenir virtuose d’un instrument. Ça remet en cause un peu tous nos environnements numériques. Pour choisir une couleur sur Word, Excel ou Photoshop, on utilise un sélecteur de couleurs différent. En pratique, même si tu utilises les mêmes couleurs, il est impossible de prendre directement une couleur dans l’un pour l’appliquer ailleurs. Pourtant, on pourrait très bien imaginer décorréler les contenus qu’on manipule (texte, images, vidéos, son…) des outils pour les manipuler, et de la même façon que je peux aller m’acheter les pinceaux et la gouache qui me conviennent bien, je pourrais faire la même chose avec mon environnement numérique en la personnalisant vraiment, sans être soumis au choix de Microsoft, Adobe ou Apple pour ma barre d’outils. C’est un projet scientifique qui me tient à cœur et qui est aussi en lien avec la collaboration numérique.
Différents instruments pour interagir avec différentes représentations d’un document, ici un graphe issu d’un tableau de données
Binaire : Par rapport à ces aspects collaboratifs, n’y a-t-il pas aussi des verrous liés à la standardisation ?
MBL : Absolument. On a beau avoir tous ces moyens de communication actuels, nos capacités de collaboration sont finalement très limitées. À l’origine d’Internet, les applications s’appuyaient sur des protocoles et standards ouverts assurant l’interopérabilité : par exemple, peu importait le client ou serveur de courrier électronique utilisé, on pouvait s’échanger des mails sans problème. Mais avec la commercialisation du web, des silos d’information se sont créés. Aujourd’hui, des infrastructures propriétaires comme Google ou Microsoft nous enferment dans des “jardins privés” difficiles à quitter. La collaboration s’établit dans des applications spécialisées alors qu’elle devrait être une fonctionnalité intrinsèque.
C’est ce constat qui a motivé la création du PEPR eNSEMBLE, un grand programme national sur la collaboration numérique, dont je suis codirecteur. L’objectif est de concevoir des systèmes véritablement interopérables où la collaboration est intégrée dès la conception. Cela pose des défis logiciels et d’interface. Une des grandes forces du système Unix, où tout est très interopérable, vient du format standard d’échange qui sont des fichiers textes ASCII. Aujourd’hui, cela ne suffit plus. Les interactions sont plus complexes et dépassent largement l’échange de messages.
C’est frustrant car on a quand même fait beaucoup de progrès en IHM, mais il faudrait aussi plus d’échanges avec les autres disciplines comme les réseaux, les systèmes distribués, la cryptographie, etc., parce qu’en fait, aucun système informatique aujourd’hui ne peut se passer de prendre en compte les facteurs humains. Au-delà des limites techniques, il y a aussi des contraintes qui sont totalement artificielles et qu’on ne peut aborder que s’il y a une forme de régulation qui imposerait, par exemple, la publication des API de toute application informatique qui communique avec son environnement. D’ailleurs, la législation européenne autorise le reverse engineering dans les cas exceptionnels où cela sert à assurer l’interopérabilité, un levier que l’on pourrait exploiter pour aller plus loin.
Cela pose aussi la question de notre responsabilité de chercheur pour ce qui est de l’impact de l’informatique, et pas seulement l’IHM, sur la société. C’est ce qui m’a amené à m’impliquer dans l’ACM Europe Technology Policy Committee, dont je suis Chair depuis 2024. L’ACM est un société savante apolitique, mais on a pour rôle d’éduquer les décideurs politiques, notamment au niveau de l’Union européenne, sur les capacités, les enjeux et les dangers des technologies, pour qu’ils puissent ensuite les prendre en compte ou pas dans des textes de loi ou des recommandations (comme l’AI ACT récemment).
Binaire : En matière de transmission, sur un ton plus léger, tu as participé au podcast Les petits bateaux sur Radio France. Pourrais-tu nous en parler ?
MBL : Oui ! Les petits bateaux. Dans cette émission, les enfants peuvent appeler un numéro de téléphone pour poser des questions. Ensuite, les journalistes de l’émission contactent un scientifique avec une liste de questions, collectées au cours du temps, sur sa thématique d’expertise. Le scientifique se rend au studio et enregistre des réponses. A l’époque, un de mes anciens doctorants [ou étudiants] avait participé à une action de standardisation du clavier français Azerty sur le positionnement des caractères non alphanumériques, et j’ai donc répondu à des questions très pertinentes comme “Comment les Chinois font pour taper sur un clavier ?”, mais aussi “Où vont les fichiers quand on les détruit ?”, “C’est quoi le com dans .com ?” Évidemment, les questions des enfants intéressent aussi les adultes qui n’osent pas les poser. On essaie donc de faire des réponses au niveau de l’enfant mais aussi d’aller un petit peu au-delà, et j’ai trouvé cela vraiment intéressant de m’adresser aux différents publics.
Numérique et Sciences Informatiques Terminale Spécialité, de Michel Beaudouin-Lafon, Benoit Groz, Emmanuel Waller, Cristel Pelsser, Céline Chevalier, Philippe Marquet, Xavier Redon, Mathieu Nancel, Gilles Grimaud. 2022.
Je suis très attaché à la transmission, je suis issu d’une famille d’enseignants du secondaire, et j’aime moi-même enseigner. J’ai dirigé et participé à la rédaction de manuels scolaires des spécialités informatiques SNT et NSI au Lycée. Dans le programme officiel de NSI issu du ministère, une ligne parle de l’interaction avec l’utilisateur comme étant transverse à tout le programme, ce qui veut dire qu’elle n’est concrètement nulle part. Mais je me suis dit que c’était peut-être l’occasion d’insuffler un peu de ma passion dans ce programme, que je trouve par ailleurs très lourd pour des élèves de première et terminale, et de laisser une trace ailleurs que dans des papiers de recherche…
Serge Abiteboul (Inria) et Chloé Mercier (Université de Bordeaux)
Les IA génératives transforment toutes les disciplines, toutes les habitudes. Elles bouleversent en particulier l’éducation, peuvent parfois paniquer les enseignants. Une spécialiste de l’IA analyse objectivement le sujet. Michèle Sebag est chercheuse émérite au CNRS. Elle est depuis 2017 membre de l’Académie des technologies, et a été membre du Conseil national du numérique. Serge Abiteboul & Chloé Mercier.
Site perso de Michele Sebag
L’irruption de ChatGPT et des intelligences artificielles génératives dans le monde de l’éducation change la donne. Pour quels résultats ? Les prédictions faites sur les impacts d’un tel changement sont variables, allant d’un futur radieux à l’apocalypse.
Ce qui change.
Comme l’avait souligné Michel Serres (Petite Poucette, 2012), l’accès à l’information à travers Wikipédia ou Google permet à chacun·e de vérifier la complétude ou la cohérence des enseignements donnés ex cathedra. Cette capacité modifie la relation des étudiant·e·s au savoir des enseignant·e·s (confiance, mémorisation).
Mais les IA génératives, ChatGPT et ses émules − LLaMA de Meta, Alpaca de Stanford, Gemini de Google, DeepSeek − vont plus loin. Une de leurs fonctions est de savoir répondre à la plupart des questions posées pour évaluer un·e étudiant·e.
Avec ChatGPT, l’étudiant·e dispose ainsi d’un simulateur énergivore de Pic de la Mirandole, ayant réponse à tout − quoique parfois privé de discernement. Chaque étudiant·e se trouve ainsi dans la chambre chinoise1, disposant d’un programme permettant de répondre aux questions, et non nécessairement de la connaissance nécessaire pour répondre aux questions.
L’enseignant·e est en face d’un double dilemme : i) à quoi sert l’enseignement si le fait de bien savoir se servir d’un ChatGPT donne les mêmes réponses ? ii) comment faire la différence entre quelqu’un qui sait, et quelqu’un qui sait se servir d’un ChatGPT ? La donne change ainsi en termes de transmission et d’évaluation des connaissances.
Contre : Coûts matériels et immatériels
Les opposants à l’ascension des ChatGPT dans le monde de l’éducation2 se fondent tout d’abord sur le fait que leur consommation en énergie n’est pas soutenable. En second lieu, ces systèmes ne sont pas fiables (”parfois privé de discernement” : les hallucinations en sont un exemple visible, mais il y a aussi toute l’information invisibilisée par suite des biais de corpus ou d’entrainement). En troisième lieu, leur impact sur la cognition est possible, voire probable.
Je m’abstiendrai de discuter les aspects énergétiques. Pour fixer les idées3, la consommation de ChatGPT (entrainement et usage pendant l’année 2023, avait été évaluée à 15 TWh (consommation énergétique de la France pendant un an : 50 TWh). Ces chiffres sont à prendre avec des correctifs de plusieurs ordres de grandeur : d’une part, chacun·e veut avoir son LLM (facteur ×100, ×1000) ; d’autre part, la consommation d’entrainement et d’usage tend à décroitre massivement pour obtenir les mêmes fonctionnalités (facteur ×1/100, ×1/1000) − ce gain étant naturellement annulé par l’effet rebond, et l’apparition de nouvelles fonctionnalités.
Je souhaite toutefois aller au-delà du fait qu’il vaudrait mieux limiter l’usage des ChatGPT pour des considérations énergétiques (comme les avions, les voitures, les ascenseurs, les cimenteries – continuer la liste). En pratique la pénétration des ChatGPT dans la société augmente.
Je m’abstiendrai aussi de discuter le manque de fiabilité. La liste des bévues de ChatGPT et al. est infinie, mais trompeuse. Le système est chaque jour moins limité que la veille ; c’est un système en interaction avec nous qui le concevons ou l’utilisons, et le système apprend de ces interactions ; la différence entre la version de novembre 2022 et la version actuelle de ChatGPT est comparée à celle qui sépare un singe d’un être humain. Nous reviendrons sur la question de savoir qui possède les données et qui contrôle le modèle.
Le troisième axe d’objection est que l’usage de ChatGPT pourrait priver l’étudiant·ed’une expérience essentielle d’apprentissage en autonomie, mais aussi, et plus gravement, de la confrontation aux sources authentiques des savoirs. Je reviendrai à cette objection centrale dans la suite.
Pour : Une éducation faisant mieux et/ou différemment avec l’IA
Plusieurs objectifs sont envisagés dans le rapport du Sénat sur IA et Éducation4. Un objectif clair consiste à utiliser les ChatGPT pour faire mieux ce qu’on fait déjà, permettant ”de suivre une classe de 25 comme une classe de 10”5. Les ChatGPT pourraient s’adapter aux élèves finement, détectant et prenant en compte les trajets cognitifs et les spécificités individuelles, en particulier les risques ou les troubles. Ils peuvent assister les professeurs, e.g. à générer des examens ou des quizz à partir de leur matériel pédagogique6 .
Ici, un danger et une opportunité sont bien identifiés. D’une part, la qualité des résultats dépend de celle du matériel pédagogique fourni. D’autre part, les dispositions d’accès à ChatGPT incluent la mise à disposition d’OpenAI des sources fournies. Il est donc hautement recommandé de disposer d’un LLM souverain pour l’enseignement7 . On pourrait imaginer un ”commun” informatique, la création d’un ChatPedia qui serait à ChatGPT ce que Wikipédia est à une encyclopédie, avec propriété collective et traçable des contributions. Voir dans ce sens le projet européen Intelligence artificielle pour et par les enseignants (AI4T)8.
D’autres objectifs, en cours d’étude, concernent le développement de fonctionnalités nouvelles (faire différemment, par exemple en proposant un tutorat personnalisé).
La cognition des enseignant·e·s
Un point épineux concerne la formation des enseignant·e·s à des usages éclairés des IA génératives. Il semble impossible, en effet, de former les élèves/étudiant·e·s à de tels usages éclairés si les enseignant·e·s n’ont pas été eux-mêmes formés. Cette logique se heurte toutefois au contexte : une fraction des enseignant·e·s avouent avec résignation ou indifférence leur éloignement total des mathématiques ; comment les attirer vers une formation formelle et roborative, pénétrant le quoi et le comment des technologies telles ChatGPT ?
La formation des formateurs a aussi un impact sur la hiérarchie des institutions et des savoirs. Bref, elle génère des résistances.
Comment avancer, dans un contexte où les perceptions de haut niveau (il est bon/nécessaire de former à l’IA) ne recoupent pas les perceptions au niveau des acteurs (l’IA est : i) incompétente ; ii) voleuse de sens/travail/valeur) ?
La cognition des apprenant·e·s
Selon l’Unesco les IAG pourraient priver les apprenant·e·s de la possibilité de développer leurs capacités cognitives et leurs compétences sociales par l’observation du monde réel, par des pratiques empiriques pouvant être des expériences, des discussions avec d’autres humains, ou par un raisonnement logique indépendant.
Ce danger peut être analysé dans le cadre du Maitre ignorant de Jacques Rancière (1987), distinguant l’enseignement ”qui explique” et celui ”qui émancipe”. Dans le premier cas, la base de discussion est que l’un·e sait et l’autre apprend ; le message implicite est que le savoir s’obtient d’un maitre.
Dans le second cas, l’objectif est non d’enseigner le savoir, mais d’établir que l’autre est capable d’apprendre tout ce qu’iel veut, au moyen de principes d’utilisation de notre propre intelligence. Il s’agit donc bien de réaliser nos capacités d’entendement autonomes.
Le danger attendu des IAG selon l’Unesco concernerait ainsi les capacités d’entendement autonomes des apprenants, donc, dans le cadre de l’enseignement ”qui émancipe”.
Une expérience
Cette expérience a été réalisée par Louis Bachaud et ses étudiant·e·s, à l’Université de Lille en 2024. L’objectif était de faire interagir un professeur, des étudiant·e·s, et un ChatGPT, de telle sorte qu’iels en sortent au bout de 2 heures, satisfaits, intrigués, motivés, ayant appris quelque chose, sans que le processus ne soit fondé sur l’identification de boucs émissaires (en particulier, ni le professeur, ni aucun élève).
Dans le premier essai, le professeur ayant posé une question générale, pertinente pour le cours (Quel est l’impact de Deezer sur l’audience d’un·eartiste?), la classe s’est divisée en petits groupes, dont chacun·e a écrit une requête et obtenu une réponse.
Les requêtes et les réponses sont mises dans un pot commun ; chacun·e cherche de quelle requête procède une réponse, appréhendant graduellement et empiriquement ChatGPT comme un système d’entrée sortie. L’intérêt de tels essais est de permettre à chacun·e, y compris le professeur, de se servir du collectif pour comprendre rapidement comment se servir d’un nouvel outil, quels en sont les usages, et comment la qualité des sorties dépend de celle des demandes. En somme, tous se perfectionnent dans l’art du prompting, art fort obscur, fort demandé et qui fait présentement la fortune des cabinets de conseil en IA génératives.
Les essais suivants ont raffiné ce schéma, en situant d’où parle la requête : réponds à cette question en sachant que je suis une musicienne de 30 ans − un DJ de 18 ans − un professeur de musique − une adolescente de 13 ans. Ces essais ont un aspect ludique (par exemple, la même commande précédée de je suis une fille de 18 ans ou je suis une femme de 18 ans ne produit pas la même réponse) conduisant à une discussion intéressante du modèle et des archétypes sous-jacents (reflétant essentiellement la culture US en 2024).
En résumé, ce type d’expérience réalise l’enseignement qui émancipe, avec un retour globalement positif des étudiant·e·s sur le savoir appris et le recul nécessaire.
Recommandations proposées
Cette première expérience va dans le sens des axes 1 et 2 du rapport cité du Sénat, concernant respectivement l’accompagnement des acteurs, et la formation d’une culture citoyenne de l’IA. D’autres expériences à l’initiative des enseignant·e·s, et leurs retours, suivant la méthodologie proposée, ou d’autres méthodologies, permettront d’affiner les savoirs qui peuvent être acquis, et comment.
Pour l’expérience considérée, les acquis obtenus reposent sur le développement de deux compétences. La première consiste, au niveau individuel, à savoir faire varier la formulation de ses demandes et sa position (d’où parle-t-on). La seconde, au niveau collectif, consiste à savoir observer les pratiques des autres et à en discuter.
La compétence exploratoire − savoir appréhender un sujet selon des points de vue différents − semble une capacité utile toutes choses égales par ailleurs. La compétence collective est peut-être plus intéressante encore ; outre l’intérêt des compétences sociales acquises, l’interaction permet de faire jeu égal avec ChatGPT.
Nous défendrons en effet la thèse selon laquelle l’entendement d’une IA ne doit pas être comparé à celui d’un être humain (ma fille n’a pas eu besoin de millions d’images de chats et de chiens pour apprendre à distinguer un chat d’un chien…) mais à celui d’un ensemble d’humains. Le fait que les IAs ne doivent pas être appréhendées au niveau de l’individu a également été souligné par Geoffrey Hinton9.
Les interactions d’un groupe humain, discutant entre eux des réponses obtenues et des bonnes questions à poser à ChatGPT, peuvent contribuer au développement des capacités cognitives et des compétences sociales, dans un contexte vivifiant.
Avertissement : l’expérience doit être suivie par les étudiant·e·s ; indépendamment de son intérêt en soi, il convient donc qu’elle soit notée.
1 Mind, Language and Society, Searle, 1998. Supposons qu’une personne glisse un message écrit en chinois sous la porte d’une chambre. Supposons dans la chambre une personne disposant d’un programme, spécifiant comment écrire une réponse en chinois (algorithme de dessin des caractères) en fonction d’un algorithme de lecture du dessin du message initial. Ce programme permet à la personne de la chambre de répondre en chinois au message chinois reçu. La personne hors de la chambre, recevant une réponse à son message, en conclut que la personne dans la chambre sait parler chinois.
2 Voir en particulier la tribune de Serge Pouts-Lajus dans le Monde de l’Éducation du 26 novembre 2024.
9G. Hinton note : Deux IA peuvent se transmettre instantanément les modèles appris par l’une ou l’autre [si les IA disposent d’une même représentation]. Cependant, la transmission des connaissances relatives à (e.g. la mécanique quantique) des enseignant·e·s vers les apprenant·e·s peut prendre beaucoup de temps et ne présente pas de garanties.
Lorsque Stanislas Dehaene et Yann Le Cun se sont rencontrés ils nous ont expliqué dans un super livre, co-écrit avec Jacques Girardon, que « l’intelligence a émergé avec la vie, elle s’est magnifiée avec l’espèce humaine » tandis que ce que d’aucun appelle « intelligence artificielle » va surtout changer le regard que nous portons sur l’intelligence naturelle, dont humaine. Ici, c’est notre collègue Max Dauchet qui prend la plume pour nous faire partager les idées clés et son analyse sur ces dernières avancées de l’informatique et des neurosciences. Serge Abiteboul et Thierry Viéville.
Voici ce que je retiens d’un petit livre de deux grands chercheurs sur l’intelligence humaine et l’intelligence machine.
Le recueil, déjà ancien mais toujours actuel, est basé sur une interviewi de deux chercheurs français mondialement connus : Stanislas Dehaene, titulaire de la chaire de psychologie cognitive expérimentale au Collège de France, pour notre cerveau et notre intelligence, et Yann Le Cun, prix Turing, pour les machines bio-inspirées comme le deep learning et leur intelligence artificielle. Ce livre est passé sous les radars des media car il privilégie la science au détriment du buzz.
Il se lit d’un trait.
Voici ce que j’en retiens.
L’intelligence est présentée comme la capacité générale à s’adapter à une situation. Selon cette définition, l’intelligence émotionnelle est un aspect de l’intelligence, à laquelle contribuent aussi bien nos sens, nos mains que notre cortex, le tout constituant un système de saisie et de traitement d’informations qui accroît les chances de survie de l’espèce en fonction de son environnement, ainsi que celles de l’individu au sein de son espèce. Il s’agit d’une organisation qui n’est pas nécessairement basée sur des neurones, ainsi l’intelligence d’une moule consiste en son aptitude à filtrer l’eau pour en tirer des nutriments. Néanmoins, au fil du temps, les systèmes interconnectant les « petites cellules grises » ramifiées se sont avérés particulièrement performants. Quant à l’humain, il a bénéficié de circonstances ayant permis l’extension de la boite crânienne et son cortex.
Tout le développement de la vie peut ainsi être vu comme un apprentissage compétitif de perpétuation. Le cerveau et son cortex ne sont pas de simples réseaux de neurones interconnectés au hasard, ils sont dotés de zones organisées et spécialisées et de processus de contrôle des connexions synaptiques sophistiqués. Les structures cérébrales les plus favorables ont été sélectionnées et figées avec plus ou moins de souplesse selon les avantages procurés. Ces zones ont constitué au fil du temps la partie innée de notre cerveau, dont les «noyaux gris» tels le striatum évoqué par Bohlerii. Le fonctionnement hérité de ces structures est inconscient, qu’il s’agisse de la régulation vitale de notre organisme, du traitement de la vision ou de tout autre signal capté par nos sens. L’évolution a conjointement à la structuration cérébrale de l’espèce préservé une plasticité cérébrale qui assure un avantage adaptatif à court terme, voire une capacité à se reconfigurer en cas d’accident ou d’invalidité. Cette plasticité permet chez l’humain une large part d’acquis à deux échelles. A l’échelle individuelle, il s’agit de l’apprentissage par l’expérience, le groupe, l’école, la culture. Cet apprentissage se traduit en structurant les circuits neuronaux par des « réglages » des synapses, qui sont des millions de milliards de points de transmission d’informations électrochimiques entre les neurones. Les connaissances ainsi apprises par un individu durant sa vie disparaissent avec lui. Mais elles sont transmises à l’échelle collective par un processus qui sort du cadre de l’hérédité génétique et est spécifique aux hominidés: la civilisation, ses constructions, ses outils, ses objets, ses cultures, ses croyances, ses sciences et ses arts – et en dernier lieu l’écriture et la capacité à se construire une histoire. Au lieu de coévoluer avec sa savane, sa mer ou sa forêt, l’humain coévolue avec l’accumulation de ses créations. Pour illustrer la dualité inné-acquis, Dehaene prend l’exemple des langues et de la causalité. Si un bébé peut apprendre n’importe quelle langue, c’est parce que toutes les langues ont des principes communs, et qu’une zone du cerveau s’est spécialisée dans leur traitement. Pour la causalité, imaginons deux populations sur une île. L’une fait le lien entre une chute de pierre et un danger, entre un crocodile et un danger, entre un signe de congénère et son attitude envers lui, autant d’exemples de lien entre cause et effet. L’autre population ne fait pas le lien, celle-ci disparaîtra et à la longue l’espèce survivante héritera de structures ou zones du cerveau «câblées» pour la recherche de causalités. De même pour les corrélations.
Ces considérations donnent la tonalité du récit de l’évolution de l’intelligence proposé dans le livre et font consensus dans les milieux scientifiques actuels. Il faut néanmoins souligner qu’il ne s’agit que de récits, pas de modèles aussi éprouvés que l’électromagnétisme ou la relativité. Il s’agit d’une tentative de dresser le tableau d’ensemble d’un puzzle dont de nombreuses pièces sont manquantes. Il en est de même du récit darwinien en général. Néanmoins en neurosciences on peut monter des expériences pour conforter ou infirmer des hypothèses, et Dehaene en relate quelques-unes, alors qu’en paléontologie ou en anthropologie on est souvent réduit à fouiller à la recherche d’indices peut-être disparus.
Pour ce qui est des machines, Le Cun fait à juste titre remarquer que le terme «intelligence machine» serait plus adéquat que celui consacré d’«intelligence artificielle» car l’intelligence est un système évolutif et interactif, dont l’organisation importe plus que le support, biomoléculaire ou silicium. On pourrait même voir l’écologie et l’évolution de la planète comme une intelligence, sans pour autant verser le moins du monde dans le culte de Gaïa (un chapitre du livre s’intitule d’ailleurs «L’intelligence de la vie»). Remarquons au passage que cette idée évoque la mouvance nord américaine de l’Intelligence design, à ceci près – nuance qui n’est pas des moindres – que dans cette vision épurée du judéo-christianisme, l’intelligence évoquée est finaliste, elle est la main de Dieu. Alors que dans le darwinisme nul objectif, nulle réalisation de dessein ne sont assignés au cheminement de l’évolution. Ce qui fait envisager en fin d’interview le dépassement de l’intelligence humaine sur le temps long, le passage par un couplage humain-machine semblant aux auteurs une étape probable. A noter qu’il n’est heureusement pas pour autant question dans l’ouvrage de transhumanisme, ensemble de micro-mouvements pseudo scientifiques surfant entre crainte d’un grand remplacement (par des cyborgs) et sur la quête d’immortalité.
Illustration du livre proposée par ChatGPT, générée par l’auteur. Elle ne reflète pas la tonalité humanisme du texte, qui nous aide au contraire à dépasser les mythes trans et post humanistes.
L’intelligence machine est survolée dans cet opuscule à travers sa comparaison à l’humain, et sous l’angle des machines bio-inspirées, comme l’est le deep learning dont Le Cun est un des pères. Le neuro et le data scientiste ne voient pas de limites a priori à l’intelligence machine, des progrès majeurs restant pour cela à accomplir dans la capacité de planification d’ensemble d’une stratégie, qui constitue encore un avantage majeur du cerveau humain. A noter que le mot «conscience» apparaît 22 fois sans être explicitement défini, car pour les interlocuteurs il est évacué de toute considération philosophique. Les activités innées sont inconscientes, celles apprises comme la conduite automobile le deviennent au fil de l’habitude. Les activités conscientes sont celles qui nécessitent de la réflexion.
Sur un plan technique, la rivalité historique entre l’approche symbolique (par le raisonnement) et l’approche connexionniste (par les réseaux neuronaux) de l’IA est brièvement rappelée. Le Cun y évoque ce que l’on a baptisé «l’hiver de l’IA», fait de discrédit et d’assèchement des financements, dans lequel les déconvenues du Perceptron avait plongé le connexionnisme. Il souligne un fait souvent passé inaperçu qui éclaire pourtant la triomphale résurgence des réseaux de neurones. Il s’agit des travaux activement menés durant cet «hiver» de deux décennies sous la modeste appellation de «traitement du signal et des images» pour ne pas agiter le chiffon rouge d’une intelligence artificielle bio-inspirées. Ces travaux ont notamment mené aux réseaux de convolution (CNN Convolution Neural Network) chers à Le Cun et qui sont à la base du succès du deep learning.
Enfin les auteurs pointent un principe essentiel, qui lui est largement connu mais qu’il est bon de marteler : «Apprendre, c’est éliminer» dit Dehaene en écho à une expression fétiche de son maître Jean-Pierre Changeux. Et l’on peut ajouter qu’apprentissage et créativité sont les deux faces d’une même pièce. Pas seulement au sens de la connaissance comme terreau du progrès, mais en un sens beaucoup plus fondamental relevant des lois du traitement de l’information au même titre que la chute de la pomme relève des lois physiques. En deux mots, apprendre par coeur ne sert à rien, si l’on apprend à reconnaître un visage en retenant par coeur chaque pixel d’un photo, on ne saura pas reconnaître la personne sur une autre photo, il faut approximer un visage par quelques caractéristiques, c’est à dire «éliminer» intelligemment les informations inutiles. Et il se crée ainsi des représentations internes du monde qui en sont des approximations utiles pour nous. Cependant, aucune pression évolutive n’a «verrouillé» l’usage de ces représentations en les limitant aux instances qui les avaient suscitées. Ainsi notre propension «câblée» à la causalité, déjà évoquée, sorte d’approximation de la logique usuelle du monde qui nous entoure, nous a fait imaginer des dieux comme causes des évènements naturels, et nourrit aussi peut-être le complotismeiii et sa recherche de causes cachées.
Max Dauchet, Professeur Émérite de l’Université de Lille.
i Stanislas Dehaene, Yann Le Cun, Jacques Girardon. La Plus Belle Histoire de l’intelligence. Des origines aux neurones artificiels : vers une nouvelle étape de l’évolution. Ed. Robert Laffont, collection La Plus Belle Histoire, 2018.
ii Sébastin Bohler, Le striatum, ed. bouquins, 2023.
iii Dans le livre seuls les dieux sont évoqués comme « inventions », le complotisme n’est pas cité.
Il n’y a plus d’enquêtes policières sans preuve numérique, sans recours massifs aux données électroniques que des criminels peuvent aussi chiffrer de manière inviolable, transférer dans des serveurs de pays peu coopératifs, rendre leur origine anonyme ou les disséminer sur le dark web. Qui des criminels ou des forces de police auront le dernier mot1 ? Charles Cuvelliez et Jean-Jacques Quisquater partagent avec le nous le bilan de ces obstacles qu’Europol vient de dresser. Pierre Paradinas et Benjamin Ninassi.
Il y a le volume des données à examiner : il se chiffre en teraoctets si pas petaoctets qu’il faut stocker, exploiter, analyser pour les autorités policières. Ce sont les fournisseurs de services numériques qui sont obligés de les conserver quelques mois2 au cas où. Ces données peuvent être de tout type, structurées comme des bases de données ou libres, comme des boites emails, des fichiers. Entre autorités policières, il n’y pas d’entente comment les données doivent être stockées, exploitées, structurées, ce qui pose ensuite un problème de coopération entre elles.
La perte de données est un autre obstacle : il y a eu une tentative d’harmoniser entre Etats membres la durée de rétention des données exploitables à titre judiciaire mais elle a été invalidée par la Cour Européenne de Justice. Depuis, chaque Etat membre a ses règles sur quelles données doivent être gardées et pendant combien de temps pour d’éventuelles enquêtes. Dans certains Etats membres, il n’y a aucune rétention prévue ou à peine quelques jours. Quand une demande arrive, les données ont évidemment disparu.
Adresse Internet multi-usage
L’épuisement des adresses Internet est un autre obstacle : les adresses dites IPv4 qui sont nées avec Internet sont toutes utilisées. Il faut les partager avec une adresse parfois pour 65 000 utilisateurs. Ces adresses sont en fait étendues avec le port IP, une extension qui dit quel service est utilisé par l’internaute (et qui donc ne l’identifie pas) et n’est pas conservée. C’est que les adresses de nouvelle génération peinent à devenir la norme puisqu’on étend justement artificiellement le pôle d’adresse IPv4. On pourrait à tout le moins imposer un nombre maximum d’internautes qui se partagent une seule adresse, dit Europol, ou imposer la rétention du port.
Jusqu’au RGPD, on pouvait accéder au titulaire d’un nom de domaine, ses coordonnées, son email, quand il l’avait ouvert. C’était précieux pour les enquêteurs mais le RPGD a amené l’ICANN, qui gère les noms de domaines non nationaux (gTLD) à ne plus rendre cette information publique. Tous les gTLD gérés par l’ICANN sont concernés. Il y a encore moyen de consulter ces données qui ne sont plus publiques mais les intermédiaires (registrars) qui assignent les noms de domaines à une organisation ou à une personne physique communiquent ces données sur base volontaire. Et surtout, rien n’est prévu pour garantir qu’une demande de renseignement policière sur le propriétaire d’un nom de domaine par une autorité policière reste anonyme. Interpol a bien proposé sa propre base de données de tous les noms de domaines impliqués dans des activités illicites mais encore faut-il les identifier. De toute façon, le système DNS qui traduit un nom de domaine en adresse IP sur Internet est exploité et détourné par les criminels pour réorienter les internautes vers des domaines qui contiennent des malwares ou de l’hameçonnage.
Chiffrement de tout
Autre défi : l’accès aux données. Les criminels prennent l’habitude de chiffrer toutes leurs données et sans clé de déchiffrement, on ne peut rien faire. Dans un Etat membre, il est possible de forcer par la contrainte un criminel à donner son mot de passe, à déverrouiller son appareil, même sans l’intervention d’un juge tandis que dans un autre Etat membre (non cité dans le rapport) un mot de passe même découvert légalement lors d’une perquisition n’est pas utilisable. Non seulement les criminels appliquent le chiffrement à leurs données mais les fournisseurs de communications électroniques vont aussi chiffrer par défaut leurs communications3. La 5G prévoit par défaut le chiffrement des données de bout en bout pour les appels vocaux si l’appel reste en 5G. L’opérateur peut même appliquer le chiffrement des données en roaming : l’appareil de l’utilisateur échange des clés de chiffrement avec son opérateur à domicile avant de laisser du trafic s’échapper sur le réseau du pays visité. Les criminels le savent et utilisent des cartes étrangères avec une clé…à l’étranger. Autre progrès fort gênant de la 5G, la technique dite de slicing, en cours de déploiement (5G SA) : elle permet de répartir le trafic d’un même utilisateur entre différents réseaux 5G virtuels à l’intérieur du réseau 5G réel pour n’optimiser les performances qu’en fonction de l‘usage (latence à optimiser ou débit à maximiser). Cela permet aux entreprises d’avoir leur réseau 5G privé dans le réseau 5G public mais cela complique la tâche des autorités policières qui doivent poursuivre plusieurs flux de trafics d’une même cible. Même les textos sont chiffrés de bout en bout avec le déploiement de RCS, un protocole dont s’est inspiré WhatsApp.
Pour des raisons de sécurité, il faut aussi chiffrer le trafic DNS, celui qui traduit le nom de domaine en adresse IP. On peut le faire au niveau bas, TLS, ce qui permet encore de suivre le trafic émis par le suspect, même s’il reste chiffré, mais parfois le trafic DNS est chiffré au niveau du protocole http, directement au niveau du navigateur ce qui le mélange avec tout le trafic internet. Ceci dit, accéder au traffic DNS de la cible requiert une forte coopération de l’opérateur télécom en plus.
Fournisseurs de communications électroniques dits OTT
Avec le Code de Communications Électronique, non seulement les opérateurs télécom traditionnels doivent permettre les écoutes téléphoniques mais aussi la myriade de fournisseurs de communications électroniques sur Internet (les Over The Top providers, ou OTT) mais ce n’est pas souvent le cas et il n’y rien qui est en place au niveau légal coercitif pour les forcer. Les techniques de chiffrement de bout en bout vont en tout cas exiger que ces opérateurs prévoient des possibilités pour les autorités policières de venir placer des équipements d’écoute comme au bon vieux temps. Mais comment vérifier qu’il n’y a pas d’abus non seulement des autorités judiciaires mais aussi des hackers.
Les cryptomonnaies
Les cryptomonnaies sont évidemment prisées par les criminels. Il est si facile d’échapper aux autorités judicaires avec les cryptomonnaies. C’est vrai qu’elles sont traçables mais les techniques pour les brouiller sont bien connues aussi : il y a le mixage qui consiste à mélanger les transactions pour dissimuler l’origine des sources. Il y a le swapping, c’est-à-dire échanger une cryptomonnaie contre un autre (et il y en a des cryptomonnaies) de proche en proche pour obscurcir le chemin suivi. Il s’agit aussi d’échanger les cryptomonnaies en dehors des plateformes ou alors via des plateformes décentralisées, sans autorité centrale à qui adresser une réquisition.
Même dans le cas d’une plate-forme centralisée soi-disant dans un pays donné, une réquisition qui y est envoyée après avoir pris du temps, ne mènera nulle part car la plate-forme ne sera pas physiquement dans le pays où elle est enregistrée. Il y a depuis, en Europe, la Travel Rule : elle oblige les plateformes qui envoient et reçoivent des cryptomonnaies à conserver le nom de l’émetteur et du bénéficiaire des fonds (cryptos).
Les techniques d’anonymisation sur Internet sont devenues redoutablement efficaces grâce à des VPNs. Ces réseaux privés sont à l’intérieur même d’internet et complément chiffrés. Ils masquent au niveau d’internet les vraies adresses IP du trafic. A côté des VPN, il y a les serveurs virtuels qu’on peut éparpiller sur les clouds en multiple exemplaires. C’est sur ces serveurs qu’est hébergé le dark web.
La coopération internationale est le dernier défi. Chaque pays ne permet pas de faire n’importe quoi au point qu’un pays doit parfois pouvoir prendre le relais d’un autre pays pour faire un devoir d’enquête non autorisé dans le pays d’origine. Il faut aussi se coordonner, éviter la déconfliction, un terme barbare qui désigne des interférences involontaires d’un Etat qui enquête sur la même chose qu’un autre État.
Tout ces constats, Europol les confirme dans son rapport sur le crime organisé publié le 18 mars. Ce dernier a bien compris le don d’ubquité que lui donne le recours à Internet et la transition vers un monde en ligne : recrutement à distance de petites mains, très jeunes, pour des tâches si fragmentées qu’elles ne se rendent pas compte pour qui et pour quoi elles travaillent, ni ne connaissent leur victime; possibilité de coordonner sans unité de temps ni de lieu les actions criminelles aux quatre coins du monde; utilisation de la finance décentralisée et des cryptomonnaies pour blanchir l’argent. Le tout avec la complicité des États qui pratiquent la guerre hybride et encouragent à l’ultra-violence, à l’infiltration des structures légales qui ont pignon sur rue, cette mise en scène visant à provoquer sidération et doute sur le bien-fondé de nos démocraties.
Depuis 2019, plusieurs nouveaux instruments législatifs de l’Union E uropéenne ont été introduits pour répondre à ces problèmes, explique Europol. Leur efficacité dépendra de la manière dont elles sont mises en œuvre dans la pratique.
Les seules histoires de démantèlement de réseau criminels qui réussissent, lorsqu’on lit les communiqués de presse entre les lignes, ont toutes une caractéristique en commune : elles sont internationales, alignées au cordeau, avec des capacités techniques reconnues des agences qui y ont travaillé. Europol a raison : ce cadre législatif a surtout pour vocation d’abattre les frontières entre pays qu’internet ne connait pas. Mais c’est une condition nécessaire, pas suffisante.
Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles) & Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT).
Pour en savoir plus : – The changing DNA of serious and organised crime EU Serious and Organised Crime Threat Assessment 2025 (EU-SOCTA), Europol. – Eurojust and Europol (2025), Common Challenges in Cybercrime – 2024 review by Eurojust and Europol, Publication Office of the European Union, Luxembourg
Notes:
1/ Cette question a pris toute son actualité avec les discussions à l’Assemblée sur la loi sur le narcotrafic qui a essayé d’imposer aux messageries chiffrées (comme WhatsApp, Signal, Telegram…) un accès à la justice quant aux échanges cryptés des narcotrafiquants et criminels. De tout façon, un amendement sur la loi NIS2 votée au Sénat devrait interdire aux messageries d’affaiblir volontairement leur sécurité.
2/ La durée de rétention des données par les opérateurs télécom en France est de 12 mois suite à un décret de la Première Ministre de l’époque E. Borne qui évoquait une menace grandissante. Il n’y a pas d’harmonisation européenne en la manière suite au recalage de e-Privacy, le RGPD qui devait s’appliquer aux opérateurs télécoms. Il y avait une directive annexe de rétention des données pour des fins judiciaires mais elle a été recalée il y a des années par la Cour Européenne de Justice. Donc, c’est resté une matière nationale, comme souvent les matières de sécurité.
3/ Un chiffrement de bout en bout des communications ou des données a toujours été présenté comme la solution inviolable et Apple a constamment mis en avant cette sécurité,expliquant ne pouvoir répondre à aucune demande d’entrer dans un iPhone saisi à un criminel ou un terroriste, mais contrainte et forcée et par le gouvernement de Grande-Bretagne, elle vient de faire volte-face, avec peut-être des conséquences pour tous les appareils Apple de la planète. En savoir plus…
1. Bonjour Pierre-Emmanuel, pouvez-vous nous dire rapidement qui vous êtes, et quel est votre métier ?
Pierre-Emmanuel
Dessia Technologies est une jeune start-up fondée en 2017 par d’anciens ingénieurs de PSA Peugeot Citroën. Nous sommes basés en région parisienne et comptons aujourd’hui une quarantaine de collaborateurs. Notre mission est d’aider les grandes entreprises industrielles, notamment dans les secteurs automobile, aéronautique, ferroviaire et naval, à digitaliser leurs connaissances et à automatiser des tâches de conception grâce à l’intelligence artificielle. Nous travaillons avec des clients prestigieux comme Renault, Valeo, Safran, Airbus, Naval Group et Alstom. Nous utilisons par exemple des algorithmes d’IA pour automatiser le design des câblages électriques ou pour générer des architectures de batteries électriques. Forts de deux levées de fonds, nous sommes soutenus par quatre fonds d’investissement, dont celui d’Orano.
2. En quoi pensez-vous que l’IA a déjà transformé votre métier ?
L’intelligence artificielle a transformé en profondeur la manière dont les ingénieurs abordent la résolution de problèmes. Avant l’arrivée de ces technologies, les ingénieurs cherchaient principalement une ou deux solutions optimales pour répondre à un problème donné. Aujourd’hui, grâce à l’IA, ils explorent un éventail beaucoup plus large de solutions possibles. Les modèles génératifs, en particulier, permettent de proposer automatiquement de nombreuses alternatives et de hiérarchiser les options selon des critères précis. Cette évolution a modifié le rôle de ces ingénieurs, qui se concentrent désormais davantage sur l’analyse et la sélection des meilleures solutions pour leur entreprise.
3. À quels changements peut-on s’attendre dans le futur ? Quelles tâches pourraient être amenées à être automatisées ? À quel horizon ?
Dans le futur, l’interaction homme-machine sera profondément redéfinie grâce aux LLM (« Large Language Models » ou grands modèles de langage). Ces modèles remplaceront les interfaces graphiques traditionnelles par des interactions écrites ou orales, rendant les outils d’ingénierie plus intuitifs et accessibles. Les ingénieurs deviendront des gestionnaires de processus automatisés, orchestrant des agents autonomes pour exécuter des tâches techniques. La plupart des activités actuellement réalisées manuellement, comme la configuration de systèmes complexes ou la gestion de chaînes logistiques, seront automatisées d’ici 5 à 10 ans. Le rôle des ingénieurs évoluera donc vers un travail décisionnel, où ils valideront les choix proposés par les systèmes automatisés, favorisant une approche collaborative et stratégique.
Ainsi, l’IA révolutionne particulièrement l’interaction et l’expérience de l’humain (UX) vis-à-vis des systèmes numériques. Les techniciens n’échangent plus via des pages HTML mais interagissent avec des éléments de savoir, grâce au langage naturel et via des messages communiquant leurs intentions de manière concise (prompt). L’IA générative permet donc de repenser les univers d’interaction traditionnels (via une « souris » et un écran) pour aller vers des univers d’interaction fluide en 3D et en langage naturel.
Demain, les interactions se feront via des agents : des automates réalisant des tâches pour le compte des ingénieurs. Les humains travailleront de concert avec des agents spécialisés, tels que les agents spécialistes de l’architecture électrique, avec ceux de l’architecture 3D et ceux des problèmes thermiques, qui se coordonneront entre eux. Ces agents permettront de résoudre des problèmes de conception en ingénierie qui sont actuellement insolubles, tels que concevoir une architecture de batterie ou un véhicule pour baisser l’empreinte carbone.
Une ou un ingénieur devra être capable de manipuler de nouvelles briques de savoir, par exemple pour s’assurer que la ligne d’assemblage d’une batterie ou d’un véhicule fonctionne bien, ou comment la faire évoluer, ainsi que le processus de conception. Il s’agit d’une mutation vers l’intégration et le développement continus (CI/CD) des produits manufacturés, réalisés en ingénierie concurrente.
On entre dans une ère dans laquelle se poseront des questions telles que celle de la sélection des tâches à automatiser et à déléguer à des agents, celle de la structuration du savoir de chaque ingénieur, de la manière de poser des questions, et de collecter des éléments de savoir.
Les ingénieurs devront aussi brainstormer, collaborer et travailler sur leur expertise pour prendre les décisions à partir des sorties des agents. La collaboration se fera au niveau décisionnel plutôt qu’au niveau opérationnel.
L’IA remet l’humain au centre. La numérisation a apporté un travail qui s’effectue de manière solitaire, seul derrière son écran. L’IA casse ce mode et pousse à développer un travail plus collaboratif ciblant les aspects stratégiques concernant la tâche à effectuer.
4. Si vous devez embaucher de nouveaux employés, quelles connaissances en informatique, en IA, attendez-vous d’eux suivant leurs postes ?
Nous recherchons des profils capables de s’adapter à l’écosystème technologique actuel et de tirer parti des outils modernes comme les LLM. Par exemple, dans les métiers marketing et vente, nous attendons une maîtrise des outils génératifs pour créer du contenu ou analyser des données de marché. Du côté des ingénieurs et data scientists, une bonne compréhension des algorithmes d’IA, des outils d’automatisation et des techniques de prototypage rapide est essentielle.
Ces remarques et les suivantes sur l’emploi des ingénieurs et autres collaborateurs concernent l’industrie en général et ne sont pas spécifiques à Dessia.
5. Pouvez-vous préciser quelles formations, à quel niveau ?
Les formations nécessaires dépendent des métiers, mais une tendance claire se dessine : la capacité d’adaptation et l’auto-apprentissage deviennent des compétences prioritaires. Pour les métiers techniques comme l’ingénierie et la data science, une spécialisation poussée reste essentielle, avec des profils de personnes ayant souvent obtenu un diplôme de doctorat ou ayant une expertise avancée en mathématiques et algorithmique. Pour d’autres postes, les recruteurs privilégient les candidats capables de se former rapidement sur des sujets émergents, au-delà de leur parcours académique, et de maîtriser les outils technologiques en constante évolution.
Les nouveaux employés devront ainsi s’adapter à de plus en plus d’exigences de la part des employeurs, ils devront avoir une expérience en IA, en pilotage de projets d’IA. Non seulement dans les domaines de l’ingénierie mais aussi des ventes. Il devront connaitre l’IA, utiliser les LLM, avoir de très bonnes qualités humaines et relationnelles.
6. Pour quelles personnes déjà en poste pensez-vous que des connaissances d’informatique et d’IA sont indispensables ?
Toutes les fonctions au sein d’une entreprise devront intégrer l’IA à leur activité, car cette technologie est en passe de devenir une nouvelle phase de digitalisation. Les entreprises qui ne suivent pas cette transformation risquent non seulement de perdre en compétitivité, mais aussi de rencontrer des difficultés à recruter des talents. L’IA deviendra un standard incontournable pour améliorer la productivité et attirer les jeunes générations, qui recherchent des environnements de travail modernes et connectés.
7. Ciblez-vous plutôt des informaticiens à qui vous faites apprendre votre métier, ou des spécialistes de votre métier aussi compétents en informatique ?
Nous ne faisons pas de distinction stricte. Chaque rôle dans l’entreprise doit intégrer l’IA, qu’il s’agisse de marketeurs utilisant des outils génératifs pour automatiser des campagnes ou d’ingénieurs chefs de projets s’appuyant sur l’IA pour optimiser la gestion de leurs plannings. Les développeurs travailleront en collaboration avec des agents IA pour accélérer leurs cycles de production, tandis que les CTO et managers utiliseront des outils intelligents pour piloter leurs indicateurs de performance. Cette polyvalence est au cœur de notre approche.
8. Pour les personnes déjà en poste, quelles formations continues vous paraissent indispensables ?
Nous privilégions des approches de transformation ciblées et pratiques plutôt que des formations classiques. Par exemple, un ou une ingénieure avec des compétences en VBA (note : Visual Basic for Applications) pourrait être accompagné pour se former à Python et à l’automatisation, augmentant ainsi sa valeur ajoutée dans l’entreprise. Un collègue secrétaire pourrait apprendre à utiliser des outils « no-code » ou des chatbots pour améliorer la gestion des intranets ou la création de contenus automatisés. Ces plans de transformation, accompagnés d’experts ou de consultants, permettront aux employés de devenir les acteurs de leur propre évolution.
9. Un message à passer, ou une requête particulière aux concepteurs de modèles d’IA ?
Nous appelons à une plus grande ouverture dans l’écosystème de l’intelligence artificielle, en particulier à travers l’open source. Cela permettrait de garantir une compétitivité équilibrée et d’éviter une concentration excessive de pouvoir entre les mains de quelques grands acteurs. Les modèles d’IA devraient être facilement personnalisables et utilisables en local pour protéger les données sensibles des entreprises. Cette approche favoriserait un écosystème plus collaboratif et innovant, permettant à un plus grand nombre d’entreprises de bénéficier des avancées technologiques.
Biais, hallucinations, création de contenus violents et activités frauduleuses : peut-on encore croire ce qu’on voit et ce qu’on entend ? Un façon d’aborder le problème est de créer des images avec une « vraie signature », indélébile et si possible indétectable, pour les distinguer de « fakes ». C’est possible et c’est ce que Jeanne Gautier et Raphaël Vienne, nous expliquent ici. Serge Abiteboul et Thierry Viéville
Vous ouvrez Instagram et tombez nez à nez avec une photo du pape en streetwear. Vous avez tout de même du mal à y croire, et vous avez bien raison ! De nombreux “deepfakes” circulent sur internet : au-delà d’être un outil formidable, l’IA générative présente donc aussi des dangers. La diffusion massive de données générées par IA impose donc de protéger leur propriété, authentifier leur auteur, détecter les plagiats etc. Une solution émerge : le watermarking (ou “tatouage numérique”) qui répond à ces attentes.
Les deux images (en Creative Commons) ci-dessus vous semblent similaires ? Elles le sont à l’œil nu mais diffèrent pourtant par de nombreux pixels.
Créer un « deep watermartking ».
Le watermarking devient de plus en plus sophistiqué. On observe une évolution des techniques de watermarking qui se basaient jusqu’ici sur des concepts assez simples comme un filigrane transparent qui recouvre l’image (« watermark » encodée dans la donnée et qui reste en apparence identique). Apparaît désormais le “deep watermarking” qui induit une altération plus subtile des données, mais qui est aussi plus robuste aux dégradations liées aux manipulations de l’image. Pour être qualifié de “deep watermarking”, un filigrane doit respecter les trois règles suivantes:
l’imperceptibilité : la distorsion doit restée invisible à l’œil humain.
la capacité : on doit pouvoir introduire de l’information dans le tatouage comme la date ou une signature.
la robustesse : le filigrane doit rester détectable même si l’on transforme l’image.
Pourquoi utilise-t-on le terme “deep” ? Parce que ces méthodes se basent sur des algorithmes d’apprentissage profond, ou “deep learning” en anglais. Il s’agit d’un procédé d’apprentissage automatique utilisant des réseaux de neurones possédant plusieurs couches de neurones cachées.
Il est possible d’appliquer de tels filigranes sur des images préexistantes par un processus qualifié “d’encodeur-décodeur” :
– Le modèle d’encodage prend deux entrées : une image brute et un message texte. Il cache le texte dans l’image en essayant de le rendre le moins perceptible possible. – Le décodeur prend en entrée l’image tatouée et tente de récupérer le texte caché.
L’encodeur et le décodeur sont entraînés pour travailler ensemble : le premier pour cacher un message dans une image sans l’altérer visuellement et le second pour retrouver le message dans cette image altérée.
Comme, en pratique, l’image tatouée peut subir des modifications (recadrage, rotation, flou, ajout de bruit), des altérations aléatoires sont appliquées aux images exemples, au cours du processus, pour entraîner le décodeur à tenir compte de ces altérations.
Mieux encore, on peut intégrer, donc encoder, le tatouage directement lors de la création d’images.
Comment fonctionnent les générateurs d’images avec watermark ?
Assez simplement, le système apprend, à partir d’un énorme nombre d’exemples, à passer d’une image où toutes les valeurs sont tirées au hasard (un bruit visuel aléatoire), en prenant en entrée une indication textuelle décrivant l’image souhaitée, à des images de moins en moins aléatoires, jusqu’à créer l’image finale. C’est cette idée de diffuser progressivement l’information textuelle dans cette suite d’images de plus en plus proches d’une image attendue qui fait le succès de la méthode.
Il est alors possible d’incorporer le watermark directement lors de la diffusion : on oriente ce processus en le déformant (on parle de biais statistique), en fonction du code secret, qu’est le watermark. Comme cette déformation ne peut être décodée, seule l’entité générant le texte, peut détecter si le tatouage, est présent.
Comment ça marche en pratique ?
Le watermarking est comme un produit « radioactif » : un modèle entraîné sur des données tatouées reproduit le tatouage présent dedans. Ainsi, si un éditeur utilise le produit tatoué d’un concurrent pour l’entraînement de ses propres modèles, les sorties de ce dernier posséderont également la marque de fabrique du premier !
Le watermarking a donc vocation de permettre aux éditeurs de modèles de génération de protéger leur propriété, puisque c’est une technique robuste pour déterminer si un contenu est généré par une IA et pour faire respecter les licences et conditions d’utilisation des modèles génératifs. Cela dit, il est essentiel de continuer à développer des techniques plus robustes, car tous les modèles open-source n’intègrent pas encore de mécanismes de watermarking.
Tom Sander, photo de son profil sur LinkedIn.
Cet article est issu d’une présentation donnée par Tom Sander chez datacraft. Tom est doctorant chez Meta et travaille sur des méthodes de préservation de la vie privée pour les modèles d’apprentissage profond, ainsi que sur des techniques de marquage numérique. Nous tenons à remercier Tom pour son temps et sa présentation.
Jeanne Gautier, Data scientist chez datacraft & Raphaël Vienne, Head of AI chez datacraft .
Angie Gaudion, chargée de relations publiques au sein de Framasoft, revient sur l’histoire de l’association, son financement, son évolution, leur positionnement dans l’écosystème numérique et, plus largement, le soutien apporté aux communs numériques. Cet article a été publié le 21 octobre 2022 sur le site de cnnumerique.fr et est remis en partage ici, les en remerciant. Serge Abiteboul et Thierry Viéville.
Framasoft, qu’est-ce que c’est ?
Pour comprendre Framasoft, il faut s’intéresser à son histoire. Née en 2001, Framasoft était d’abord une sous-catégorie du site participatif Framanet, lequel regroupait des ressources à destination des enseignants et mettait en avant des logiciels éducatifs gratuits (libres et non-libres). Framasoft est devenu « indépendant » et 100% libre plusieurs années plus tard. Mais il y a déjà une volonté de valoriser le logiciel libre dans le milieu de l’enseignement. D’ailleurs, en juin 2002, Framasoft est, avec l’AFUL, à l’origine de l’action Libérons les logiciels libres à l’école.
Entre 2001 et 2004, un collectif se structure autour de la promotion des logiciels libres et propose des interventions sur ces questions (conférences, ateliers, stands, etc.). C’est en 2004 que Framasoft se structure en association avec pour objet la promotion du logiciel libre et de la culture libre. Pour atteindre cet objectif, apparaissent entre 2004 et 2014 plusieurs projets comme les Framakey (clé USB contenant des logiciels libres permettant de les utiliser sans avoir à les installer sur son ordinateur), Framabook (maison d’édition d’ouvrages sous licence libre), Framablog (chroniques autour du Libre, traductions originales et annonces des nouveautés de l’ensemble du réseau Framasoft), etc…
À partir de 2011 (10 ans), Framasoft se diversifie et décide de proposer des services libres en ligne : Framapad (mars 2011), Framadate (juin 2011), Framacalc (février 2012), Framindmap et Framavectoriel (février 2012), Framazic (novembre 2013) et Framasphère (2014).
En octobre 2014, nous lançons la campagne “Dégooglisons Internet” dont l’objectif est de proposer des services libres alternatifs à ceux proposés par les géants du web à des fins de monopole et d’usage dévoyé des données personnelles. Cette campagne nous fait connaître du grand public et, entre 2014 et 2017, on déploie jusqu’à 38 services en ligne. L’égalité de l’accès à ces applications est un engagement fort : en les proposant gratuitement, Framasoft souhaite promouvoir leur usage envers le plus grand nombre et illustrer par l’exemple qu’un Internet décentralisé et égalitaire est possible. En parallèle, nous lançons en 2016 le Collectif des Hébergeurs Alternatifs Transparents Ouverts Neutres et Solidaires (CHATONS). Framasoft cherche a faire connaître et essaimer des hébergeurs alternatifs aux GAFAM proposant des services libres et respectueux de la vie privée. En effet, nous ne souhaitons pas concentrer toutes les démarches alternatives, mais plutôt partager le gâteau avec d’autres structures (nous ne voulons pas devenir “le Google du libre”).
2017 marque la fin de la campagne “Dégooglisons Internet” : les services existants sont conservés mais nous n’en déployons plus de nouveaux. Depuis 2019, nous avons fermé progressivement une partie de ces services. Nous avons fait le choix de ne conserver que ceux qui n’étaient pas proposés ailleurs et ceux qui sont les plus utilisés. Par exemple, le service Framalistes (un outil de listes de discussion) est utilisé par 960 000 personnes et envoie chaque jour près d’un million d’emails. On sait donc que si l’on supprime ce service, cela manquera aux personnes qui l’utilisent. La décision d’arrêter certains services a aussi été prise en fonction de la difficulté technique à les maintenir. Par exemple Framasite était utilisé par de nombreuses personnes mais présentait une dette technique énorme. Néanmoins, depuis son arrêt, nous nous rendons bien compte que le service manque parce qu’il n’y a pas vraiment d’alternatives.
2017, c’est aussi le lancement de la campagne Contributopia. On est parti du constat que pour changer le positionnement des gens, il fallait non plus faire pour elleux, mais avec elleux (faire ensemble). L’objectif est de décloisonner le libre de son ornière technique pour développer ses valeurs éthiques et sociales (donc politiques). On a donc décidé de proposer différents dispositifs pour valoriser la contribution (méconnue, mal valorisée et trop complexe) et outiller celles et ceux qui veulent « faire » des communs. Contributopia prend de nombreuses formes : on continue à développer des alternatives lorsqu’elles n’existent pas (PeerTube, Mobilizon), on essaie de faire émerger d’autres acteurices à l’international, on développe les partenariats avec des structures dont les valeurs sont proches des nôtres pour les outiller (archipélisation). Et on essaie d’être le plus résilient en faisant tout cela, tout en valorisant la culture du partage.
En 2021, nous actons, par la modification des statuts, que Framasoft est devenue une association d’éducation populaire aux enjeux du numérique et des communs culturels. Notre objet social n’est plus de faire la promotion du logiciel libre, mais de transmettre des connaissances, des savoirs et de la réflexion autour de pratiques numériques émancipatrices. Pourtant, nous continuons à offrir des services en ligne afin de démontrer que ces outils existent et sont des alternatives probantes aux services des géants du web. Nous transmettons davantage désormais connaissances et savoirs-faire sur ces outils et accompagnons les internautes dans leur autonomisation vis-à-vis des géants du web.
Aujourd’hui, 37 personnes sont membres de l’association, dont 10 salariées. Mais cela ne veut pas dire que nous ne sommes que 37 à contribuer. On estime qu’entre 500 et 800 personnes nous aident régulièrement, que ce soit pour de la traduction d’articles, des propositions de lignes de codes pour les logiciels que nous développons, du repérage de bugs, des illustrations, des contributions au forum d’entraide de la communauté… Pour finir, en terme de nombre de bénéficiaires, on ne peut donner qu’une estimation parce que nous ne collectons quasiment aucune donnée, mais on estime à 1,2 millions le nombre de personnes qui utilisent nos services chaque mois. Cependant, on ne s’attarde pas vraiment sur les chiffres, on ne veut pas d’un monde où on compte, d’un monde où on analyse systématiquement l’impact.
Quel est votre modèle de financement ?
Framasoft est actuellement une association dont le modèle économique repose sur le don, donc exclusivement sur des financements privés. Notre budget s’élève à 630 000 € en 2021. 98,42 % de ce montant est financé par les dons, qui se répartissent entre :
12,56 % provenant de fondations
85,86 % provenant de dons de particuliers.
Les 1,58 % qui ne proviennent pas des dons viennent de la vente de prestations. Par exemple, Framasoft a développé pour le site apps.education.fr un plugin d’authentification unique sur PeerTube, permettant de connecter au service la base de tous les login et mots de passe d’enseignants à l’échelle nationale et d’éviter ainsi qu’ils aient à se créer un nouveau compte.
Ce budget sert principalement à financer les salaires des 10 salariées. À cela s’ajoutent quelques prestations techniques (développement et design), du soutien à d’autres acteurs du logiciel libre et des frais de fonctionnement divers.
Cette question du mode de financement est particulièrement importante pour nous. Le modèle du don convient parfaitement à Framasoft même si nous sommes conscients qu’il est difficilement reproductible pour des projets de grande envergure. Cela reste un choix politique. Nous savons que de nombreuses structures du libre sont aujourd’hui financées par les géants du net. C’est un paradoxe assez fort, d’autant plus qu’il est évident que toutes ces structures préféreraient que ce ne soit pas le cas. Mais en l’absence d’autres sources de financement, elles n’ont pas toujours le choix. Et il serait vraiment dommage que les services qu’elles proposent n’existent pas faute de financement. Il y a donc un réel enjeu de soutien de ces structures, notamment pour assurer leur pérennité.
Que pensez-vous de l’idée ou des réactions de celles et ceux qui se disent que les initiatives du libre ont du mal à « passer à l’échelle » ?
Pour mettre fin à la dépendance envers les géants du numériques, un moyen d’y parvenir, sans avoir besoin d’acquérir une taille critique et une position dominante est de s’associer à d’autres projets et de collaborer ensemble à une autre vision du web.
On peut s’interroger sur cette recherche permanente de croissance : s’il est indispensable que des services alternatifs aux modèles dominants du net existent, est-ce nécessaire qu’une seule et même entité concentre l’ensemble des services ? La centralisation peut conférer une certaine force, mais chez Framasoft nous avons fait le choix de nous passer de cette force : l’essaimage nous semble le meilleur moyen de passer à l’échelle. Si la priorité est de mettre fin à la dépendance envers les géants du numériques, un moyen d’y parvenir, sans avoir besoin d’acquérir une taille critique et une position dominante est de s’associer à d’autres projets et de collaborer ensemble à une autre vision du web.
Chez Framasoft, nous ne souhaitons pas le passage à l’échelle. D’ailleurs, nous ne savons même pas de quelle échelle on parle ! Dans les faits, l’association a grossi au fil du temps, mais notre volonté est d’avoir une croissance limitée et raisonnée parce que nous sommes convaincus qu’il vaut mieux être plusieurs acteurs qu’un seul. Nous ne voulons donc pas centraliser les usages et les profits. Si le but premier est d’avoir de plus en plus d’utilisateurs de logiciels libres – ce qui était l’objectif avec « Dégooglisons Internet » – peu importe que ce soit chez Framasoft ou chez d’autres. Tant que les internautes ont fait leur migration vers des logiciels libres, pour nous le « passage à l’échelle » est réussi. C’est une vision différente des structures productivistes : nous visons un « passage à l’échelle » côté utilisateurs et non côté entreprise. La priorité, pour nous, c’est le changement de société.
Le passage à l’échelle pose aussi, selon nous, la question de la façon dont on traite les humains. Si l’on veut prendre soin des humains il faut des relations de confiance et d’empathie entre individus. Tisser de tels liens nous semble difficile si l’on est sans cesse en train de doubler nos effectifs. Cela explique aussi le fait que nous soyons une association de cooptation où tout le monde se connaît.
Du fait de notre ADN issu du logiciel libre, nous ne voulons pas entrer dans le modèle du capitalisme néolibéral et du productivisme. Nous tenons à défendre le modèle associatif. Nous sommes dans un contexte où les associations et leurs financements sont très mis à mal par les politiques publiques de ces dernières années. C’est donc un véritable choix que de garder ce modèle pour le soutenir et montrer que le modèle économique du don est viable.
Nous visons un « passage à l’échelle » côté utilisateurs et non côté entreprise. La priorité, pour nous, c’est le changement de société.
Si on rentre plus précisément dans la perspective de « Dégooglisation », comment vous positionnez-vous par rapport aux géants du web ?
Notre objectif est de permettre à toute personne qui le souhaite de remplacer les services des géants du web qu’elle utilise par des alternatives. Nous ne nous positionnons donc pas vraiment en concurrence car, en tant qu’hébergeurs de services alternatifs, nous ne cherchons pas systématiquement à reproduire à l’identique les services de ces géants. Par exemple, le service Framadate propose exactement les mêmes fonctionnalités que Doodle (et même davantage puisqu’il permet de réaliser des sondages classiques). En revanche, le service Framapad (basé sur le logiciel Etherpad) ne fait pas exactement la même chose que Google Docs et pourtant nous considérons que c’est son alternative. Il ne permet pas la gestion d’un espace de stockage, mais simplement l’édition collaborative en simultané d’un texte. Le service est chrono-compostable : le pad disparaît après un certain délai. Nous avons proposé une alternative à Google Drive avec le service Framadrive que nous avons limité à 5 000 comptes, lesquels ont été pris d’assaut. Nous allons prochainement proposer un nouveau service alternatif de cloud et d’édition collaborative basé sur le logiciel Nextcloud. Ce service ne sera pas commercialisé et sera proposé aux organisations actrices du progrès et de la justice sociale avec des limitations (taille du stockage, nombre d’utilisateurs) pour leur montrer qu’il existe une alternative viable et les inciter à transiter dans un second temps vers des services libres plus complets proposés par certaines structures membres du collectif CHATONS. Notre objectif est de permettre d’expérimenter et ensuite de rediriger vers d’autres partenaires proposant, eux, des solutions pérennes.
J’aimerais que l’on (les hébergeurs de services alternatifs) devienne une alternative viable à grande échelle. Ce serait possible, mais cela voudrait dire que nous aurions changé très fortement le système. On peut se dire qu’avec le mouvement fort des communs, et pas uniquement des communs numériques, une partie de la population a pris conscience qu’il est temps de mettre en cohérence ses usages numériques avec ses valeurs. Il demeure cependant ardu de mesurer si ces initiatives augmentent. La question est : que mesure-t-on ? Est-ce que l’on mesure le nombre de projets ? Ou le nombre de personnes dans ces communautés qui gèrent des communs ? À cet égard, il y a un enjeu de sous-estimation parce que beaucoup de « commoners » s’ignorent comme tels. Les bénévoles qui gèrent des associations sportives sont un bon exemple. Ensuite, plus que de dénombrer ces projets, il serait plus intéressant d’en analyser l’impact sur la société. Cela implique de financer la recherche pour qu’elle travaille sur ces questions, ce qui n’est pas suffisamment le cas aujourd’hui. Même si quelques projets existent néanmoins, tels que le projet de recherche TAPAS (There Are Platforms As Alternatives).
L’État contribue-t-il aujourd’hui aux communs ? Cette contribution est-elle souhaitable ?
L’État contribue aux communs. Par exemple, l’Éducation nationale propose la page apps.education.fr qui référence un ensemble de services pédagogiques en ligne basés sur du logiciel libre. Mais l’État est paradoxal : il contribue aux communs et signe des accords avec Microsoft pour implémenter Windows sur les postes informatiques des écoles. De plus, cette initiative de l’Éducation nationale est très bonne, mais elle reste très méconnue du corps enseignant. Au-delà de la contribution, il y a donc aussi un enjeu important de promotion.
Cette contribution étatique ne nous pose aucun problème, tant que cela ne crée pas de situations de dépendance et qu’il n’y a pas d’exigences de ces institutions publiques en termes d’impact ou de performance. Il faudrait, notamment, que les financements soient engagés sur plusieurs années. Il faudrait aussi arrêter le financement de projets et privilégier des financements du fonctionnement. Ensuite, nous pensons que certains dispositifs mis en place ces dernières années par les pouvoirs publics ne devraient pas exister. Par exemple, le contrat d’engagement républicain, qui doit obligatoirement être signé par une association pour qu’elle puisse bénéficier de financements publics, met ces dernières dans des positions difficiles. L’association doit satisfaire aux principes qui y sont présentés et, si tel n’est pas le cas, le financement peut être suspendu, voire il peut être demandé de rembourser les montants précédemment engagés. Mais la forme sous laquelle ce contrat est rédigé est si floue que les termes utilisés peuvent être interprétés de multiples manières. Il devient alors assez facile de tordre le texte pour mettre la pression, voire faire cesser l’activité d’une association. Ce n’est donc pas le principe de ce contrat qui me gêne, mais ce flou sur la formulation des termes qui fait qu’on ne sait pas où est la limite de son application. C’est d’ailleurs ce qui s’est passé le 13 septembre dernier quand le Préfet de la Vienne a sommé par courrier la ville et la métropole de Poitiers de retirer leurs subventions destinées à soutenir un village des alternatives organisé par l’association Alternatiba Poitiers. Pour quel motif ? Au sein de cet événement, une formation à la désobéissance civile non-violente a été jugée « incompatible avec ce contrat d’engagement républicain ». Signée par 65 organisations (dont Framasoft), une tribune rappelle que la désobéissance civile relève de la liberté d’expression, du répertoire d’actions légitimes des associations et qu’elle s’inscrit dans le cadre de la démocratie et de la république.
Framasoft est aussi signataire de la tribune Pour que les communs numériques deviennent un pilier de la souveraineté numérique européenne parue en juin dernier. En effet, dans le cadre des travaux engagés au sein de l’Union européenne, il semblait important de rappeler quel’espace numérique ne doit pas être laissé à la domination des plateformes monopolistiques. Et que pour pallier à cela, l’Union européenne doit, plus que jamais, initier des politiques d’envergure afin que les communs numériques puissent mieux se développer et permettre de maintenir une diversité d’acteurs sur le Web. Plus largement, on peut se demander pourquoi il devrait y avoir une contrepartie au développement d’un commun. Pourquoi le simple fait de créer, développer et maintenir un commun ne suffirait-il pas ?
Communs numériques et ergonomie font-ils bon ménage ?
C’est le marronnier quand on vient à parler de communs numériques ! Pour ce qui concerne les services en ligne alternatifs, il est évident que le design et l’expérience utilisateur devraient être davantage pris en compte et mériteraient des financements plus importants au sein des structures qui les développent. Chez Framasoft, nous faisons appel depuis plusieurs années à des designers pour réfléchir aux interfaces des logiciels que nous développons (PeerTube et Mobilizon). Cette prise de conscience est récente. Dans le monde du libre, il me semble que, pendant assez longtemps, il n’y a pas vraiment eu de réflexion quant à l’adoption des outils par le plus grand nombre.
Les services numériques tels qu’ils existent aujourd’hui nous ont fait prendre des habitudes et ont créé un réflexe de comparaison. Mais passer d’iPhone à Android ou l’inverse génère aussi des crispations. Le passage aux communs en générera naturellement aussi et peut-être plus. C’est d’ailleurs un discours que l’on porte beaucoup chez Framasoft : c’est plus simple d’aller au supermarché que d’avoir une pratique éthique d’alimentation. Il en va de même en ligne. Modifier ses pratiques numériques demande un effort. Mais cela ne veut évidemment pas dire que l’on ne peut pas améliorer les interfaces de nos services. Cependant, cela nécessite des financements qui ne sont pas toujours faciles à avoir. Les utilisateurs de services libres devraient en prendre conscience pour davantage contribuer à l’amélioration de ces communs. On peut lier ce mécanisme à la problématique du passager clandestin : tout le monde souhaite des services libres avec une meilleure expérience utilisateur mais peu sont prêts à les financer. Aujourd’hui, les projets de communs ont des difficultés à trouver des financements pour cet aspect de leurs services.
Angie Gaudion, chargée de relations publiques au sein de Framasoft,
Anne-Marie Kermarrec est une informaticienne française, professeure à l’École polytechnique fédérale de Lausanne. Elle est internationalement reconnue pour ses recherches sur les systèmes distribués, les systèmes « pair à pair », les algorithmes épidémiques et les systèmes collaboratifs d’apprentissage automatique. Elle fait partie du Conseil présidentiel de la science français et est nouvellement élue à l’Académie des Sciences. Elle contribue régulièrement à binaire, et a publié en 2021 « Numérique, compter avec les femmes », chez Odile Jacob.
Binaire : Tout d’abord, peux-tu nous retracer rapidement le parcours depuis la petite fille en Bretagne jusqu’à la membre Académie des sciences ?
AMK : Oui, je viens de Bretagne ; je suis la petite dernière d’une fratrie de quatre. On a tous suivi des études scientifiques. Au lycée, en seconde, j’avais pris option informatique pour aller dans un lycée particulier à Saint-Brieuc. À la fac, j’hésitais entre l’économie, les maths, l’informatique, et j’ai choisi l’informatique, un peu par hasard j’avoue. Je n’avais pas une idée très précise de ce que c’était mais il se trouve que j’avais un frère informaticien, qui avait fait un doctorat, et ça avait l’air d’un truc d’avenir !
J’ai découvert la recherche pendant mon stage de maîtrise, où j’ai étudié les architectures des ordinateurs. Puis, en DEA et en thèse, j’ai bifurqué vers les systèmes distribués, là encore, un peu par hasard. La façon de travailler en thèse m’a beaucoup plu, et m’a donné envie de continuer dans cette voie. J’ai donc poursuivi un postdoc à Amsterdam, avec un chercheur qui m’a beaucoup inspiré, Andy Tanenbaum. C’est là que j’ai commencé à travailler sur les systèmes distribués à large échelle – mon sujet principal de recherche depuis. Après deux ans comme maitresse de conférences à Rennes, j’ai passé cinq ans comme chercheuse pour Microsoft Research à Cambridge en Angleterre. C’était très chouette. Ensuite, je suis devenue directrice de recherche Inria et j’ai monté une équipe sur les systèmes pair-à-pair, un sujet très en vogue à l’époque. Cela m’a conduite à créer une start-up, Mediego, qui faisait de la recommandation pour les journaux en ligne et exploitait les résultats de mon projet de recherche. En 2019, juste avant le Covid, j’ai vendu la start-up. Depuis je suis professeure à l’EPFL. J’y ai monté un labo, toujours sur les systèmes distribués à large échelle, avec des applications dans l’apprentissage machine et l’intelligence artificielle.
Binaire : Pourquoi est-ce que tu n’es pas restée dans l’industrie après ta start-up?
AMK : La création de ma start-up a été une expérience très enrichissante techniquement et humainement. On était parti d’un algorithme que j’avais développé et dont j’étais très fière, mais finalement, ce qui a surtout fonctionné, c’est un logiciel de création de newsletters qu’on avait co-construit avec des journalistes. Les joies du pivot en startup. Et à un moment donné, j’avais un peu fait le tour dans le sens où, même si ce n’était pas une grosse boîte, une fois qu’on avait trouvé notre marché, je m’occupais essentiellement des sous et des ressources humaines… et plus tellement, plus assez, de science. Donc j’ai décidé de revenir dans le monde académique que je n’avais pas complètement quitté, puisque j’y avais encore des collaborations. J’ai aimé mon passage dans l’industrie, mais j’aime aussi la nouveauté, et c’est aussi pour ça que j’ai pas mal bougé dans ma carrière. Et après quelque temps, le monde académique me manquait, les étudiants, les collègues. Et puis, ce qui me plaît dans la recherche : quand on a envie, on change de sujet. On fait plein de choses différentes, on jouit d’une énorme liberté et on est entouré d’étudiants brillants. J’avais vraiment envie de retrouver cette liberté et ce cadre.
Et puis, au vu de tout ce qui se passe avec ces grosses boîtes en ce moment, je me félicite d’être revenue dans le monde académique ; je n’aurais pas du tout envie de travailler pour elles maintenant….
Binaire : Ton premier amour de chercheuse était le pair-à-pair. Est-ce que tu peux nous expliquer ce que c’est, et nous parler d’algorithmes sur lesquels tu as travaillé dans ce cadre ?
(1)(2)
Architecture centralisée (1), puis pair-à-pair (2). Source: Wikimedia commons.
AMK : Commençons par les systèmes distribués. Un système distribué consiste en un ensemble de machines qui collaborent pour exécuter une application donnée ; l’exemple type, ce serait les data centers. On fait faire à chaque machine un morceau du travail à réaliser globalement. Mais à un moment donné, il faut quand même de la synchronisation pour mettre tout ça en ordre.
La majorité des systèmes distribués, jusqu’au début des années 2000, s’appuyait sur une machine, qu’on appelle un serveur, responsable de l’orchestration des tâches allouées aux autres machines, qu’on appelle des clients. On parle d’architecture client-serveur. Un premier inconvénient, qu’on appelle le passage à l’échelle, c’est que quand on augmente le nombre de machines clientes, évidemment le serveur commence à saturer. Donc il faut passer à plusieurs serveurs. Comme dans un restaurant, quand le nombre de clients augmente, un serveur unique n’arrive plus à tout gérer, on embauche un deuxième serveur, puis un autre, etc. Un second problème est l’existence d’un point de défaillance unique. Si un serveur tombe en panne, le système en entier s’écroule, alors même que des tas d’autres machines restent capables d’exécuter des tâches.
Au début des années 2000, nous nous sommes intéressés à des systèmes distribués qui n’étaient plus seulement connectés par des réseaux locaux, mais par Internet, et avec de plus en plus de machines. Il est alors devenu crucial de pouvoir supporter la défaillance d’une ou plusieurs machines sans que tout le système tombe en panne. C’est ce qui a conduit aux systèmes pair-à-pair.
Binaire : On y arrive ! Alors qu’est-ce que c’est ?
AMK : Ce sont des systèmes décentralisés dans lesquels chaque machine joue à la fois le rôle de client et le rôle de serveur. Une machine qui joue les deux rôles, on l’appelle un pair. En termes de passage à l’échelle, c’est intéressant parce que ça veut dire que quand on augmente le nombre de clients, on augmente aussi le nombre de serveurs. Et si jamais une machine tombe en panne, le système continue de fonctionner !
Bon, au début, les principales applications pour le grand public étaient… le téléchargement illégal de musique et de films avec des systèmes comme Gnutella ou BitTorrent ! On a aussi utilisé ces systèmes pour de nombreuses autres applications comme le stockage de fichiers ou même des réseaux sociaux. Plus récemment, on a vu arriver de nouveaux systèmes pair-à-pair très populaires, avec la blockchain qui est la brique de base des crypto-monnaies comme le Bitcoin.
Maintenant, entrons un peu dans la technique. Dans un système distribué avec un très grand nombre de machines (potentiellement des millions), chaque machine ne communique pas avec toutes les autres, mais juste avec un petit sous-ensemble d’entre elles. Typiquement, si n est le nombre total de machines, une machine va communiquer avec un nombre logarithmique, log(n), de machines. En informatique, on aime bien le logarithme car, quand n grandit énormément, log(n) grandit doucement.
Maintenant, tout l’art réside dans le choix de ce sous-ensemble d’environ log(n) machines avec qui communiquer. La principale contrainte, c’est qu’on doit absolument éviter qu’il y ait une partition dans le réseau, c’est-à-dire qu’il doit toujours exister un chemin entre n’importe quels nœuds du réseau, même s’il faut pour cela passer par d’autres nœuds. On va distinguer deux approches qui vont conduire à deux grandes catégories de systèmes pair-à-pair, chacune ayant ses vertus.
La première manière, dite « structurée », consiste à organiser tous les nœuds pour qu’ils forment un anneau ou une étoile par exemple, bref une structure géométrique particulière qui va garantir la connectivité du tout. Avec de telles structures, on est capable de faire du routage efficace, c’est-à-dire de transmettre un message de n’importe quel point à n’importe quel autre point en suivant un chemin relativement court. Par exemple, dans un anneau, en plaçant des raccourcis de façon astucieuse, on va pouvoir aller de n’importe quelle machine à n’importe quelle autre machine en à peu près un nombre logarithmique d’étapes. Et la base de tous ces systèmes, c’est qu’il y a suffisamment de réplication un peu partout pour que n’importe quelle machine puisse tomber en panne et que le système continue à fonctionner correctement.
La seconde manière, dite « non structurée », se base sur des graphes aléatoires. On peut faire des choses assez intéressantes et élégantes avec de tels graphes, notamment tout ce qui s’appelle les algorithmes épidémiques (j’avais parlé de ça dans un autre article binaire). Pour envoyer un message à tout un système, je l’envoie d’abord à mes voisins, et chacun de mes voisins fait la même chose, etc. En utilisant un nombre à peu près logarithmique de voisins, on sait qu’au bout d’un nombre à peu près logarithmique d’étapes, tout le monde aura reçu le message qui s’est propagé un peu comme une épidémie. Cela reste vrai même si une grande partie des machines tombent en panne ! Et le hasard garantit que l’ensemble reste connecté.
On peut faire évoluer en permanence cette structure de graphe aléatoire, la rendre dynamique, l’adapter aux applications considérées. C’est le sujet d’un projet ERC que j’ai obtenu en 2008. L’idée était la suivante. Comme je dispose de ce graphe aléatoire qui me permet de m’assurer que tout le monde est bien connecté, je peux construire au-dessus n’importe quel autre graphe qui correspond bien à mon application. Par exemple, je peux construire le graphe des gens qui partagent les mêmes goûts que moi. Ce graphe n’a même pas besoin de relier tous les nœuds, parce que de toute façon ils sont tous connectés par le graphe aléatoire sous-jacent. Et dans ce cas-là, je peux utiliser ce réseau pour faire un système de recommandation. En fait, au début, je voulais faire un web personnalisé et décentralisé. C’était ça, la « grande vision » qui a été à la base de la création de ma startup. Sauf que business model oblige, finalement, on n’a pas du tout fait ça 😉 Mais j’y crois encore !
(1)
(2)
Architectures pair-à-pair: structurée (ici en anneau (1)) et routage aléatoire (2). Source: Geeks for geeks.
Binaire : Et aujourd’hui, toujours dans le cadre du pair-à-pair, tes recherches portent sur l’apprentissage collaboratif.
AMK : Oui, l’apprentissage collaboratif, c’est mon sujet du moment ! Et oui, on reste proche du pair-à-pair, mon dada !
Dans la phase d’entraînement de l’apprentissage automatique classique, les données sont rapatriées dans des data centers où se réalise l’entrainement. Mais on ne veut pas toujours partager ses données ; on peut ne pas avoir confiance dans les autres machines pour maintenir la confidentialité des données.
Donc, imaginons des tas de machines (les nœuds du système) qui ont chacune beaucoup de données, qu’elles ne veulent pas partager, et qui, pour autant, aimeraient bénéficier de l’apprentissage automatique que collectivement ces données pourraient leur apporter. L’idée est d’arriver à entraîner des modèles d’apprentissage automatique sur ces données sans même les déplacer. Bien sûr, il faut échanger des informations pour y arriver, et, en cela, l’apprentissage est collaboratif.
Une idée pourrait être d’entrainer sur chaque machine un modèle d’apprentissage local, récupérer tous ces modèles sur un serveur central, les agréger, renvoyer le modèle résultat aux différentes machines pour poursuivre l’entrainement, cela s’appelle l’apprentissage fédéré. A la fin, on a bien un modèle qui a été finalement entraîné sur toutes les données, sans que les données n’aient bougé. Mais on a toujours des contraintes de vulnérabilité liées à la centralisation (passage à l’échelle, point de défaillance unique, respect de la vie privée).
Alors, la solution est d’y parvenir de manière complètement décentralisée, en pair-à-pair. On échange entre voisins des modèles locaux (c’est à dire entrainés sur des données locales), et on utilise des algorithmes épidémiques pour propager ces modèles. On arrive ainsi à réaliser l’entrainement sur l’ensemble des données. Ça prend du temps. Pour accélérer la convergence de l’entrainement, on fait évoluer le graphe dynamiquement.
Cependant, que ce soit dans le cas centralisé ou, dans une moindre mesure, décentralisé, l’échange des modèles pose quand même des problèmes de confidentialité. En effet, même si les données ne sont pas partagées, il se trouve qu’il est possible d’extraire beaucoup d’informations des paramètres d’un modèle et donc du client qui l’a envoyé. Il y a donc encore pas mal de recherches à faire pour garantir que ces systèmes soient vraiment respectueux de la vie privée, et pour se garantir d’attaques qui chercheraient à violer la confidentialité des données : c’est typiquement ce sur quoi je travaille avec mon équipe à l’EPFL.
Binaire : L’entraînement dans un cas distribué, est-ce que cela ne coûte pas plus cher que dans un cas centralisé ? Avec tous ces messages qui s’échangent ?
AMK : Bien sûr. Il reste beaucoup de travail à faire pour réduire ces coûts. En revanche, avec ces solutions, il est possible de faire des calculs sur des ordinateurs en local qui sont souvent sous-utilisés, plutôt que de construire toujours plus de data centers.
Binaire : Cela rappelle un peu les problèmes de coût énergétique du Bitcoin, pour revenir à une autre application du pair-à-pair. Peux-tu nous en parler ?
AMK : Un peu mais nous sommes loin des délires de consommation énergétique du Bitcoin.
En fait, au début, quand j’ai découvert l’algorithme original de la blockchain et du Bitcoin, je n’y ai pas du tout cru, parce que d’un point de vue algorithmique c’est un cauchemar ! En systèmes distribués, on passe notre vie à essayer de faire des algorithmes qui soient les plus efficaces possibles, qui consomment le moins de bande passante, qui soient les plus rapides possibles, etc… et là c’est tout le contraire ! Un truc de malade ! Bon, je regrette de ne pas y avoir cru et de ne pas avoir acheté quelques bitcoins à l’époque…
Mais c’est aussi ça que j’aime bien dans la recherche scientifique : on se trompe, on est surpris, on apprend. Et on découvre des algorithmes qui nous bluffent, comme ceux des IA génératives aujourd’hui.
Binaire : Tu as beaucoup milité, écrit, parlé autour de la place des femmes dans le numérique. On t’a déjà posé la question : pourquoi est-ce si difficile pour les femmes en informatique ? Peut-être pas pour toi, mais pour les femmes en général ? Pourrais-tu revenir sur cette question essentielle ?
AMK : On peut trouver un faisceau de causes. Au-delà de l’informatique, toutes les sciences “dures” sont confrontées à ce problème. Dès le CP, les écarts se creusent entre les filles et les garçons, pour de mauvaises raisons qui sont des stéréotypes bien ancrés dans la société, qui associent les femmes aux métiers de soins et puis les hommes à conduire des camions et à faire des maths… Pour l’informatique, la réforme du lycée a été catastrophique. La discipline n’avait déjà pas vraiment le vent en poupe, mais maintenant, quand il faut abandonner une option en terminale, on délaisse souvent l’informatique. Et ça se dégrade encore dans le supérieur. La proportion de femmes est très faible dans les écoles d’ingénieurs, et ça ne s’améliore pas beaucoup. Pour prendre l’exemple d’Inria, la proportion de candidates entre le début du recrutement et l’admission reste à peu près constante, mais comme elle est faible à l’entrée on ne peut pas faire de miracles…
Pourtant, une chose a changé : la parité dans le domaine est devenue un vrai sujet, un objectif pour beaucoup, même si ça n’a pas encore tellement amélioré les statistiques pour autant. Ça prend beaucoup de temps. Un sujet clivant est celui de la discrimination positive, celui des quotas. Beaucoup de femmes sont contre dans les milieux académiques parce qu’elles trouvent ça dévalorisant, ce que je peux comprendre. Je suis moi-même partagée, mais parfois je me dis que c’est peut-être une bonne solution pour accélérer les choses…
Binaire : Bon, de temps en temps, cela change sans quota. Même à l’Académie des sciences !
AMK : C’est vrai, magnifique ! Je suis ravie de faire partie de cette promo. Une promo sans quota plus de 50 % de femmes parmi les nouveaux membres Académie des sciences en général, et 50 % en informatique. On a quand même entendu pendant des années qu’on ne pouvait pas faire mieux que 15-20% ! Pourvu que ça dure !
Serge Abiteboul, Inria, et Chloé Mercier, Université de Bordeaux.

 Sa passion pour la programmation débute tôt : à quinze ans, il conçoit un jeu de Mastermind qui lui vaut, en 1982, le Prix scientifique Philips pour les jeunes. C’est la première de nombreuses distinctions. En 2007, il obtient le Grand prix de philosophie de l’Académie française pour le livre, “Les Métamorphoses du calcul. Une étonnante histoire de mathématiques”. Dans cet ouvrage, il montre comment les mathématiques et la logique se transforment au XXᵉ siècle avec l’intégration de la notion de calcul. Il reçoit le Grand prix d’informatique Inria – Académie des sciences en 2023, et la Médaille Histoire des Sciences et Épistémologie de cette même académie en 2024. Autant de signes qu’il fut l’un des meilleurs scientifiques de son domaine, mais aussi bien plus que cela.
Sa passion pour la programmation débute tôt : à quinze ans, il conçoit un jeu de Mastermind qui lui vaut, en 1982, le Prix scientifique Philips pour les jeunes. C’est la première de nombreuses distinctions. En 2007, il obtient le Grand prix de philosophie de l’Académie française pour le livre, “Les Métamorphoses du calcul. Une étonnante histoire de mathématiques”. Dans cet ouvrage, il montre comment les mathématiques et la logique se transforment au XXᵉ siècle avec l’intégration de la notion de calcul. Il reçoit le Grand prix d’informatique Inria – Académie des sciences en 2023, et la Médaille Histoire des Sciences et Épistémologie de cette même académie en 2024. Autant de signes qu’il fut l’un des meilleurs scientifiques de son domaine, mais aussi bien plus que cela.




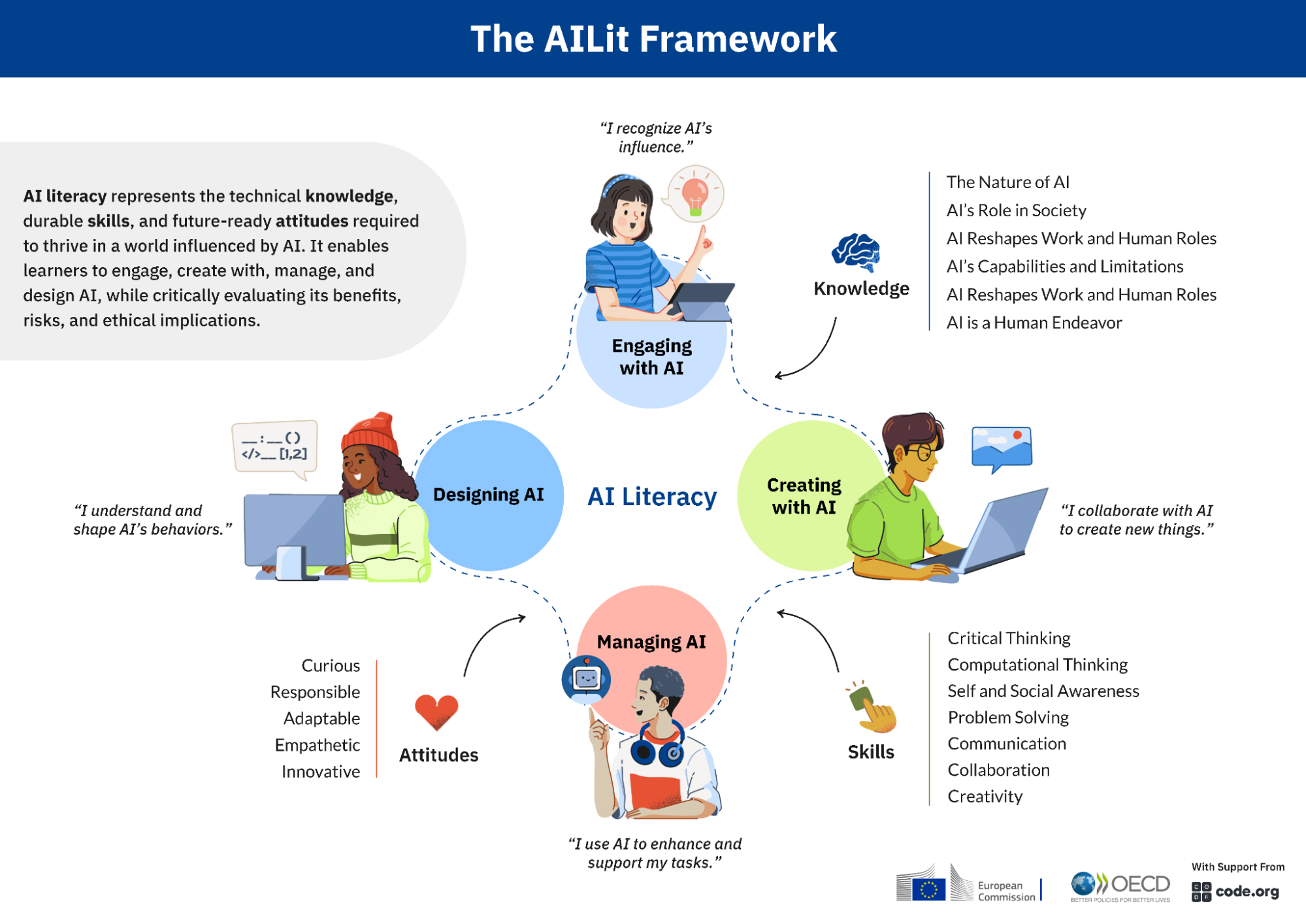














 Notre collègue du Cnam, Stéphane Natkin, Prof émérite, suite à l’écoute sur France Inter de Madame Virginie Schwarz, directrice de Météo France à propos du remplacement des modèles mathématiques de prévision par des modèles d’IA… a imaginé ce petit conte. Pierre Paradinas & Thierry Viéville.
Notre collègue du Cnam, Stéphane Natkin, Prof émérite, suite à l’écoute sur France Inter de Madame Virginie Schwarz, directrice de Météo France à propos du remplacement des modèles mathématiques de prévision par des modèles d’IA… a imaginé ce petit conte. Pierre Paradinas & Thierry Viéville.